
- 1 Database本番運用 Vol2 — DMS × Aurora Global Database × DynamoDB Streams × AWS Backup
- 1.1 1. なぜDatabase本番運用 Vol2か — Vol1 基礎運用からの架橋 + 移行/グローバル/バックアップの3軸
- 1.2 2. AWS Database 移行・展開 4本柱整理 + 選定マトリクス + 用途別決定木
- 1.3 3. DMS本番運用 ★山場1
- 1.3.1 3-1. Replication Instance 設計 — Multi-AZ / スペック選定 / VPC 配置
- 1.3.2 3-2. Endpoint 設定 — Source / Target / IAM / SSL
- 1.3.3 3-3. Task 種類と使い分け — Full Load + CDC が本番推奨
- 1.3.4 3-4. Schema Conversion Tool (SCT) — 異種 DB 移行のスキーマ変換
- 1.3.5 3-5. LOB 制限対応 — Limited LOB Mode vs Full LOB Mode
- 1.3.6 3-6. Validation 設定 — 差分検出 / 不整合検知
- 1.3.7 3-7. CDC 性能監視 — Replication Lag / CloudWatch メトリクス
- 1.4 Terraform 実装例 — DMS 3要素
- 1.4.1 aws_dms_replication_instance (本番 Multi-AZ)
- 1.4.2 aws_dms_endpoint (Source Oracle / Target Aurora PostgreSQL)
- 1.4.3 aws_dms_replication_task (Full Load + CDC / Validation 有効)
- 1.4.4 4-2. 1秒以内レプリケーションの仕組みと監視
- 1.4.5 4-3. Headless DR 設計パターン
- 1.4.6 4-4. 計画 Failover 手順 (Managed Planned Failover)
- 1.4.7 4-5. 非計画 Failover 手順 (Detach & Promote)
- 1.4.8 4-6. Failback 手順 (旧 Primary を Secondary として再結合)
- 1.4.9 4-7. Aurora Global Failover シーケンス (mermaid02)
- 1.5 5. DynamoDB Streams + Global Tables本番運用 ★山場3
- 1.6 6. Backup戦略本番運用 ★山場4
- 1.6.1 6.1 AWS Backup 統合設計 — Backup Plan + Vault + Resource Assignment
- 1.6.2 6.2 Aurora Backtrack — 72時間以内の短期操作ミス即時復旧
- 1.6.3 6.3 PITR (Point-In-Time Recovery) 設計 — RDS/Aurora/DynamoDB 別
- 1.6.4 6.4 Snapshot Lifecycle Policy — 多段保持 + Cold Storage 最適化
- 1.6.5 6.5 AWS Backup Vault Lock — WORM 保護の選択基準
- 1.6.6 6.6 バックアップコスト試算(月次目安)
- 1.7 7. 詰まりポイント7選 + アンチパターン演習5問
- 1.7.1 詰まり1: DMS LOB 移行でのデータ欠損(Limited LOB の罠)
- 1.7.2 詰まり2: スキーマ差異による DMS 変換エラー(SCT 未使用の罠)
- 1.7.3 詰まり3: Aurora Global Database Failback 忘れ(Primary 戻し忘れ)
- 1.7.4 詰まり4: DynamoDB Streams 24時間保持限界を超えた Consumer 遅延
- 1.7.5 詰まり5: Global Tables Conflict 解決漏れ(LWW 競合でデータ消失)
- 1.7.6 詰まり6: Backup Restore 時間の過小評価(RPO/RTO 試算ミス)
- 1.7.7 詰まり7: Cross-Region Snapshot 転送コスト爆発(コスト試算なし)
- 1.8 8. まとめ + Vol3予告 + 落とし穴10選 + 全12軸+Database Vol1+Vol2+Serverless Vol1+Vol2 クロスリンク
Database本番運用 Vol2 — DMS × Aurora Global Database × DynamoDB Streams × AWS Backup

本記事は AWS本番運用 全12軸 + Database Vol1 (RDS × Aurora × DynamoDB 基礎運用) を完遂した中堅エンジニアに向けた、Database 進化的運用記事です。DMS / Aurora Global Database / DynamoDB Streams / AWS Backup の4本柱を全12軸統合視点で再統合し、移行・グローバル展開・バックアップ戦略の3軸で本番品質の Database 運用パターンを確立します。
Vol1 からの進化軸 (Foundation → Evolution)
- Vol1 = RDS / Aurora / DynamoDB の3本柱基礎運用 (Multi-AZ / Read Replica / Partition Key 設計)
- Vol2 = 移行 (DMS) + グローバル (Aurora Global) + ストリーミング (DynamoDB Streams) + バックアップ (AWS Backup) の4本柱進化運用
- Vol1+Vol2 統合で「設計→運用→移行→DR→バックアップ」のフルライフサイクルを完成
関連 deep-dive シリーズ (本Vol2でクロスリンク誘導)
- Aurora Backup/Restore/DR シリーズ (8節分割 deep-dive)
- Aurora No-Human Login (IAM Database Authentication deep-dive)
1. なぜDatabase本番運用 Vol2か — Vol1 基礎運用からの架橋 + 移行/グローバル/バックアップの3軸
Vol1 で RDS / Aurora / DynamoDB の基礎3本柱を習得したエンジニアが次に直面するのは、「基礎運用の壁」だ。Multi-AZ を設定し、Read Replica を追加し、Backup を有効化した — それでも本番障害は止まらない。原因を追うと、多くが「Database 層のライフサイクル設計の欠落」に行き着く。
全12軸 (IAM / EKS / 復旧 / AI / セキュリティ / コスト / マルチアカウント / Observability / Network / DevOps) を完遂した後に Database 軸を学ぶことで、「なぜ DB が詰まると他の軸の施策が無力化するのか」が明確になる。IAM で最小権限を整備し、EKS でコンテナ基盤を磨き、Observability でメトリクスを可視化した — にもかかわらず、データストア層の設計ミスが根本原因の障害は後を絶たない。DB 層のライフサイクル設計 (移行・グローバル化・バックアップ) は、他のどの軸の施策とも交差する基盤であり、Vol2 で正しく設計することで全12軸の統合価値が最大化される。
Vol1 段階では、データの永続化と基本的な可用性確保が主な課題だった。しかしサービスが成長し、グローバル展開・データ移行・コンプライアンス要件が加わると、基礎運用スキルだけでは対処しきれない領域が現れる。以下の5つの壁がその代表例だ。
本記事の構成と読み方
本記事は §1〜§8 の8節構成だ。§1 (本節) で Vol1 との架橋と4本柱の全体像を把握し、§2 で選定フレームワーク・マトリクス・Terraform 実装例を理解した上で、§3〜§6 の各サービス深掘りに進む設計になっている。
| セクション | 内容 | 推奨読者 |
|---|---|---|
| §1 (本節) | Vol1 架橋 / 4本柱全体像 / 12軸接続点 | 全員 |
| §2 | 選定マトリクス / 決定木 / Terraform 実装 | 設計者 / IaC 担当 |
| §3 | DMS 本番運用 (移行★山場1) | 移行プロジェクト担当 |
| §4 | Aurora Global 本番運用 (DR★山場2) | DR 設計担当 |
| §5 | DynamoDB Streams + Global Tables (CDC★山場3) | ストリーミング設計担当 |
| §6 | AWS Backup 戦略 (Backup★山場4) | コンプライアンス / 運用担当 |
| §7 | 詰まりポイント7選 + 演習5問 | 実践学習者 |
| §8 | まとめ + クロスリンクハブ (26記事) | 全員 |
基礎運用者が直面する 5 つの壁
壁 1: オンプレ・異種 DB からのデータ移行
既存オンプレの Oracle / SQL Server から Aurora への移行、あるいは他クラウドの PostgreSQL から RDS への移行では、単純な mysqldump / pg_dump では本番ダウンタイムが数時間に及ぶ。ダウンタイムを最小化しながら TB 規模のデータを正確に移植し、移行後の整合性を保証するには、DMS (Database Migration Service) の Full Load + CDC (Change Data Capture) を組み合わせた継続的レプリケーションが必要だ。Schema Conversion Tool (SCT) で異種 DB スキーマを変換する手順も必須になる。
壁 2: Single Region の限界
Vol1 の Multi-AZ は同一 Region 内の AZ 障害に対する HA (高可用性) だ。Region 全体に影響が及ぶ大規模障害に対して、Single Region 構成は無力になる。グローバルサービスや金融・医療分野では「RPO = 1 秒以内・RTO = 5 分以内」のクロスリージョン DR 要件が求められる。Aurora Global Database はこれを実現するサービスだが、Failover Runbook を事前に整備しないと、実際の障害時に判断ミス・人為操作ミスで RTO 違反が発生する。
壁 3: CDC 連携要件
DynamoDB の変更をリアルタイムで Kinesis / OpenSearch / Redshift に連携したい、RDS の更新イベントを下流の分析基盤に流したい — こうした CDC (Change Data Capture) 要件は Vol1 の基礎設定だけでは実現できない。DynamoDB Streams + Lambda Trigger の組み合わせ、または DMS の CDC モードが必要になる。設定ミス (StreamViewType 誤選択・Lambda Trigger の Batch Size 過大) は Iterator Age 増加から処理遅延・データ欠損につながる。
壁 4: コンプライアンス対応バックアップ
金融規制・医療法・GDPR 等に基づく要件では「証明可能な WORM 保護」「最低 7 年間の保持」「Cross-Account / Cross-Region への Vault 分離」が求められる。Vol1 の自動バックアップや手動スナップショットだけでは、これらの規制要件を満たせない。AWS Backup Vault Lock の Compliance Mode を正しく設定することで、削除不可の WORM バックアップを実現できるが、設定ミスは深刻な問題になる。
壁 5: 厳格化する RPO/RTO 要件
Vol1 段階では「数時間で復旧」という許容度があっても、SLA が厳格化されると「RPO 秒単位・RTO 5 分以内」要件が課される。Aurora PITR の最小単位は 5 分であり、これだけでは厳格要件を満たせない。Aurora Global Failover / Backtrack (MySQL) / AWS Backup Cross-Region の組み合わせで初めて厳格な RTO/RPO を実現できる。復元演習を四半期で実施し、実効性を継続的に証明する体制も必要だ。
厳格な RPO/RTO 要件に対応するには、障害の種類 (AZ 障害 / Region 障害 / データ誤削除 / アプリ論理バグ) ごとに異なるリカバリ手段を使い分ける設計が必要だ。AZ 障害なら Multi-AZ Failover (自動・数十秒)、Region 障害なら Aurora Global Failover (手動・30〜60秒)、データ誤削除なら PITR (最大 5 分前) または Backtrack (Aurora MySQL で秒単位巻き戻し)、アプリ論理バグによる大量誤更新なら AWS Backup からの Restore — それぞれに対応した Runbook を整備し、Drill で所要時間を計測することが本番 SLA 保証の前提条件となる。
Vol2 で解決する 4 つの本番課題
以上の5つの壁を突き崩す4本柱が、本 Vol2 のコアだ。4本柱は独立したサービスではなく、Database 本番運用の4フェーズ (移行・グローバル化・CDC 連携・バックアップ) に対応した統合フレームワークとして機能する。
課題 1: 移行 (Migration) — DMS の Full Load + CDC で、本番ダウンタイムを最小化しながらデータを正確に移植する。SCT で異種 DB スキーマを変換し、Validation で移行後の整合性を保証する。
課題 2: グローバル展開 (Global Distribution) — Aurora Global Database で Primary + Secondary 構成を組み、1 秒以内の Replication Lag でクロスリージョン DR を実現する。Failover Runbook を標準化し、四半期 Drill で RTO/RPO を継続検証する。Headless DR 構成 (Secondary を Read-only Endpoint 専用で維持) により、DR コストを最小化しながらリージョン障害対応力を確保する。
課題 3: ストリーミング連携 (Stream Integration) — DynamoDB Streams + Lambda Trigger で変更データを下流に連携する。Global Tables でマルチリージョン双方向レプリケーションを実現し、Iterator Age 監視で処理遅延を事前検知する。StreamViewType の選択 (NEW_AND_OLD_IMAGES 推奨) と Lambda Trigger の Batch Size・Parallelization Factor 設計が本番品質の鍵だ。
課題 4: バックアップ戦略 (Backup Strategy) — AWS Backup で複数 DB を統合管理し、Vault Lock × Cross-Account / Cross-Region でコンプライアンス要件を満たす。四半期 Restore Drill で Backup の実効性を証明する。Native Backup との役割分担 (短期 PITR は Native・長期統合管理は AWS Backup) を明確にしてコスト最適化する。
Database 本番運用ライフサイクルへの拡張
Vol1 で習得した基礎スキルは、Vol2 で Database フルライフサイクル管理へ拡張される。
| フェーズ | Vol1 基礎 | Vol2 進化 |
|---|---|---|
| データ移行 | mysqldump / 手動 Import | DMS Full Load + CDC / SCT 異種 DB 変換 |
| クロスリージョン DR | Multi-AZ (同一 Region 内) | Aurora Global Failover (Cross-Region) |
| CDC 連携 | なし | DynamoDB Streams + Lambda / DMS CDC |
| バックアップ管理 | 各 DB 個別 / 自動バックアップ | AWS Backup 統合 / Vault Lock WORM |
| 復元演習 | なし | 四半期 Restore Drill / RTO 計測 |
| コンプライアンス | KMS 暗号化 (基礎) | Vault Lock Compliance Mode / Cross-Account |
全12軸との接続点 — Database Vol2 は何軸と連携するか
Database Vol2 の4本柱は、全12軸の各施策と深く連携する。以下の接続点を理解することで、Database 運用を孤立した施策として扱わず、12軸統合設計の文脈で正確に位置づけられる。
第1軸 IAM との接続: DMS Endpoint の暗号化キー管理・AWS Backup の Vault アクセス制御・Aurora Global Database の Cluster IAM ポリシー — これらすべてが IAM の最小権限設計を前提とする。Backup の Cross-Account Copy では、コピー先アカウントへの KMS Key 共有と IAM Role 信頼関係の設計が必須だ。
第3軸 復旧との接続: Aurora Global Failover Runbook は復旧シリーズで扱う Chaos Engineering / Multi-Region Active-Active 設計と直結する。DMS による Data Restore (移行先からの逆戻し) も DR ユースケースの一形態だ。AWS Backup の Restore Drill は復旧シリーズで培った演習設計手法を Database 文脈に適用する。
第8軸 Observability との接続: DMS の CloudWatch メトリクス (CDCLatencySource / CDCLatencyTarget) / Aurora Global の AuroraGlobalDBReplicationLag / DynamoDB Streams の IteratorAge — これらすべてが Observability シリーズで学んだメトリクス設計・アラート閾値設定の実践対象だ。
第10軸 DevOps との接続: DMS Task の Terraform 管理・AWS Backup Plan の IaC 化・Aurora Global Database の Terraform 構成は、DevOps シリーズで扱う IaC パイプライン (Terraform × CodePipeline / GitHub Actions OIDC) で継続的に管理する。
本 Vol2 で得られる 4 つの成果
成果 1: 4本柱選定フレームワーク — DMS / Aurora Global / DynamoDB Streams / AWS Backup を、ユースケース・要件に応じて定量的に選定できるようになる。
成果 2: DMS 本番運用能力 — Replication Instance のサイジング・LOB 列設定・Full Load + CDC フロー・SCT スキーマ変換を Terraform で実装し、Validation で整合性を保証できる。
成果 3: Aurora Global 本番運用能力 — Primary / Secondary 構成・Replication Lag 監視・Failover Runbook 標準化・Failback 手順まで含め、クロスリージョン DR を本番品質で運用できる。
成果 4: バックアップ戦略統合能力 — AWS Backup Plan で複数 DB を統合管理し、Vault Lock × Cross-Account / Cross-Region でコンプライアンス要件を満たすバックアップ体制を構築・運用できる。
Vol2 の4本柱を習得することで、Database 運用は「設計して動かす」フェーズから「移行・拡張・保護しながら継続的に改善する」フェーズへと進化する。Vol1 の基礎運用能力と組み合わせることで、小規模スタートアップから金融・医療分野の大規模システムまで対応できる Database フルライフサイクル設計力が確立される。
- 第1軸 IAM (4記事):
Vol1: IAM ポリシー設計入門 /
Vol2: マルチアカウント IAM 設計 /
Vol3: Permission Inventory 自動化 /
Vol4: STS クロスアカウント - 第2軸 EKS (3記事):
Vol1: クラスター設計 / IRSA / ALB Ingress /
Vol2: Observability / Fluent Bit / Container Insights /
Vol3: GitOps / ArgoCD - 第3軸 復旧 (4記事):
Vol1: Backup × Cross-Region DR /
Vol2: Chaos Engineering × FIS /
Vol3: ランブック × 自動化 /
Vol4: Multi-Region Active-Active - 第4軸 AI (2記事):
Vol1: Bedrock Agents 本番運用 /
Vol2: Knowledge Bases × RAG - 第5軸 セキュリティ (3記事):
Vol1: セキュリティ運用入門 /
Vol2: SOC 統合運用 /
Vol3: IAM Access Analyzer × KMS Multi-Region - 第6軸 コスト (1記事):
Vol1: Cost Explorer × Budgets × Compute Optimizer - 第7軸 マルチアカウント (1記事):
Vol1: Organizations × Control Tower × Landing Zone - 第8軸 Observability (1記事):
Vol1: Application Signals × SLO × X-Ray - 第9軸 Network (2記事):
Vol1: Transit Gateway × VPC Lattice × PrivateLink /
Vol2: Hybrid Connectivity (Direct Connect × VPN) - Network Vol2 マルチアカウント網: Vol2 TGW×PrivateLink×DX×Peering×VPN マルチアカウント網本番設計
マルチアカウント環境のTGW Route Table分離・PrivateLink設計・Direct Connect Resilient構成 - 第10軸 DevOps (2記事):
Vol1: CodePipeline × CodeBuild × CodeDeploy × GitHub Actions OIDC /
Vol2: Container × CodeArtifact × SAM × Amplify - 第11軸 Database本番運用 (2記事):
Vol1: RDS × Aurora × DynamoDB 基礎運用 /
本記事 Vol2: DMS × Aurora Global × Streams × Backup 進化運用 - 第12軸 Serverless本番運用 (2記事):
Vol1: Lambda × API GW × Step Functions /
Vol2: EventBridge × SQS × SNS × Kinesis
- ← Vol1: RDS × Aurora × DynamoDB 基礎運用 — Multi-AZ / Read Replica / PITR / Partition Key 設計
- → 本記事 Vol2: DMS × Aurora Global Database × DynamoDB Streams × AWS Backup — 移行・グローバル展開・ストリーミング・バックアップ戦略の4本柱進化運用
- Aurora 個別 deep-dive: Aurora Backup/Restore/DR 完全ガイド / Aurora No-Human Login (IAM Database Authentication)
- 痛点1: DMS Replication Instance 過少設計による LOB 列移行失敗・CDC遅延
- 痛点2: Aurora Global Database Failover 手順未整備による RTO/RPO 違反
- 痛点3: DynamoDB Streams Lambda Trigger の Iterator Age 増加による処理遅延
- 痛点4: AWS Backup Vault Lock 設定漏れによる誤削除・コンプライアンス違反
- 痛点5: Cross-Region Snapshot コピーのコスト爆発 (転送料金見落とし)
Vol1: RDS × Aurora × DynamoDB 基礎運用を読む
2. AWS Database 移行・展開 4本柱整理 + 選定マトリクス + 用途別決定木
AWS Database 移行・展開の実務では、4つのサービスそれぞれが担う役割を正確に理解した上で、要件に応じた組み合わせを選定する必要がある。「移行したい」「グローバル展開したい」「変更データを連携したい」「コンプライアンス対応バックアップが必要」— ユースケースを整理してから最適なサービスを選定することが、設計の第一歩だ。
4本柱の選定ミスは、設計段階でコスト増・性能劣化・DR 目標未達を招く。例えば「Aurora Global Database を移行ツールとして使う」「DMS を継続 DR レプリカとして使う」「DynamoDB Streams でバッチ集計を代用する」「AWS Backup と Native Backup を重複管理する」といったアンチパターンは、実プロジェクトで繰り返し発生する。本セクションで選定マトリクス・決定木・アンチパターンを体系化し、設計段階での選定ミスを事前に防ぐ。
4本柱 選定マトリクス (8軸評価)
以下のマトリクスで4サービスの特性を比較し、ユースケースに最適なサービスを選定する。
| 評価軸 | DMS | Aurora Global Database | DynamoDB Streams | AWS Backup |
|---|---|---|---|---|
| 主目的 | DB 移行・継続 Replication | Multi-Region DR / 読み込み分散 | CDC / イベント連携 | 統合バックアップ管理 |
| 対象 DB | RDS / Aurora / Oracle / SQL Server 等 | Aurora のみ | DynamoDB のみ | RDS / Aurora / DynamoDB / EFS / EBS 等 |
| レプリカ方式 | 非同期 (Full Load + CDC) | 物理レプリカ (ログ転送) | ストリーム (変更ログ) | スナップショット (定期) |
| Replication Lag | 数秒〜数分 (ネットワーク依存) | 1 秒以内 (SLA) | リアルタイム (Lambda Trigger) | ポイントイン時刻 (PITR) |
| Multi-Region | クロスリージョン Endpoint 可 | Primary + Secondary 最大5 | Global Tables で双方向 | Cross-Region Copy 対応 |
| コンプライアンス | SCT スキーマ変換・Validation | KMS 暗号化 | KMS 暗号化 | Vault Lock WORM・Cross-Account |
| コスト要因 | Replication Instance 時間料金 | Secondary クラスタ維持費 | Lambda 起動回数 | ストレージ + 転送料金 |
| 主なユースケース | 移行・異種DB変換・CDC 継続 | DR / グローバル展開 / 読み込み分散 | イベント駆動連携・下流分析 | 統合管理・長期保存・規制対応 |
統合アーキテクチャパターン
4本柱は単独での利用だけでなく、組み合わせることで本番環境の複合要件を満たす。
パターン A: DMS Full Load + CDC 継続移行
移行フェーズで DMS Full Load を完了した後、CDC モードで継続レプリケーションを維持し、カットオーバータイミングで移行元への接続を切り替える。移行中のダウンタイムを最小化しながら、ソースとターゲットの整合性を Validation で継続確認する。Full Load 完了後の CDC 切替タイミングでは、ソース側の変更が Target に追いつくまでの Lag を監視し、Lag がほぼ 0 になった時点でカットオーバーを実施する。
Replication Instance のサイジングは移行規模に応じて選定する。小規模テスト移行は dms.t3.medium、本番移行 (〜1TB) は dms.c5.xlarge 以上、LOB 列が多いメモリ集約型は dms.r6i.xlarge 以上が目安だ。Multi-AZ Replication Instance を選択するとスタンバイが別 AZ に配置され、Replication Instance 障害時の中断を防ぐ。本番移行では Multi-AZ を標準とする。
パターン B: Aurora Global Database + Headless DR
Primary Region で書き込みを処理し、Secondary Region に Headless (Application 未接続) の Reader クラスタを維持する。Primary 障害時に Secondary を Promote して Writer 昇格させ、Application のエンドポイントを切り替える DR 構成だ。Write Forwarding を無効化した Headless 構成が最も費用対効果が高い。Replication Lag が 1 秒以内に保たれていることを AuroraGlobalDBReplicationLag メトリクスで継続監視する。
パターン C: DynamoDB Streams + Global Tables
DynamoDB Streams の NEW_AND_OLD_IMAGES で全変更をキャプチャし、Lambda Trigger で下流の Kinesis / OpenSearch / Redshift に連携する。Global Tables でマルチリージョン双方向レプリケーションを組み合わせ、Last Writer Wins の Conflict 解決を Application 側の冪等キーで管理する。Iterator Age が継続的に増加する場合は Lambda Concurrency 上限を確認し、Reserved Concurrency を確保する。
Streams の Lambda Trigger は Batch Size の設定が性能に大きく影響する。Batch Size を小さくすると起動回数が増えてコストが上がり、大きくすると単一バッチ処理に時間がかかり Iterator Age が増加する。本番では Batch Size = 10〜100 で開始し、Iterator Age と Lambda 実行時間のメトリクスをもとに調整する。DLQ (Dead Letter Queue) を設定し、処理失敗レコードを再処理・分析できる体制を整える。
パターン D: AWS Backup 統合管理 + Vault Lock
Backup Plan で RDS / Aurora / DynamoDB を一括管理し、Vault Lock の Compliance Mode で削除不可の WORM バックアップを実現する。Cross-Account / Cross-Region Copy で Vault を分離し、マルチアカウント環境でのバックアップガバナンスを統合する。Compliance Mode 適用前に 72 時間の Cooling-off Period が必要なため、本番投入前に Governance Mode で動作を検証する。
Backup Plan の rule 設定では、日次バックアップ (短期保持・Cold Storage 移行) と週次フルバックアップ (長期保持・Cross-Region Copy) を組み合わせることでストレージコストを最適化できる。Tag ベースの Resource Selection により、新規リソースが BackupRequired = true タグを持てば自動的にバックアップ対象に追加される。この仕組みは IaC (Terraform) によるインフラ管理と組み合わせることで、リソース追加漏れによるバックアップ対象外を防ぐ。
5問で選定: ユースケース別 Quick Reference
以下の5問に答えることで、どの本柱を優先的に設計すべきかを即時判断できる。
Q1: 移行元 DB は PostgreSQL / MySQL / Oracle / SQL Server のいずれか? → Yes → DMS (Full Load + CDC) が第一選択。同一エンジン間なら mysqldump + Zero Downtime パターンも検討余地あり。
Q2: 複数 Region にまたがる DR または読み込み分散が必要か? → Yes + Aurora → Aurora Global Database。Yes + DynamoDB → DynamoDB Global Tables。双方が必要なら両者を組み合わせる。
Q3: DB の変更を下流の分析基盤やイベント処理に連携するか? → DynamoDB → DynamoDB Streams + Lambda Trigger。RDS / Aurora → DMS CDC Mode または Amazon RDS / Aurora の標準 Event + CloudWatch Logs Subscription。
Q4: 複数サービス (RDS + DynamoDB + EFS 等) の Backup を統合管理したいか? → Yes → AWS Backup Plan で統合し Vault Lock を適用。単一サービスの短期保持のみ → Native Backup で十分。
Q5: WORM 保護・長期保持 (7年以上) ・Cross-Account Vault 分離が必要か? → Yes → AWS Backup Vault Lock Compliance Mode。コンプライアンス要件なし → Governance Mode または Native Backup。
5問すべてに「No」の場合は、Vol1 で習得した RDS / Aurora / DynamoDB の Native 設定 (Multi-AZ / Read Replica / PITR / 自動バックアップ) で十分だ。Vol2 の4本柱が必要になる時点で、システムの成熟度や要件の複雑性が一段階上がっていることを意味する。コストと運用負荷の増加を許容できる要件・ビジネスインパクトが伴う場合のみ、Vol2 の各本柱を段階的に導入する判断が重要だ。
Aurora Backup / DR 詳細との住み分け
本 Vol2 では Aurora Global Database の移行・グローバル展開・Failover Runbook を扱う。Aurora Backup の詳細 (Snapshot 自動化・Cross-Region DR・PITR 精度・Restore 演習手順・Backtrack 詳細) については、専用の deep-dive シリーズに委ねる。Aurora No-Human Login (IAM Database Authentication / RDS Proxy / Secrets Manager ローテーション) についても、専用シリーズを参照されたい。
Aurora Backup/Restore/DR 完全ガイド (Snapshot × Cross-Region × Vault Lock × Restore Drill)
Aurora No-Human Login (IAM Database Authentication × RDS Proxy × Secrets Manager)
4本柱 組み合わせアンチパターン
DMS のみで継続 Replication を代替する: DMS は移行ツールであり、長期継続 Replication には向かない。本番稼働後の継続レプリケーションには Aurora Global Database または DynamoDB Global Tables を本来の用途で利用する。
Aurora Global で同期書き込みを期待する: Aurora Global は非同期レプリカだ。Secondary への直接書き込みは Write Forwarding 経由で Primary に転送されるが、遅延が発生する。強整合性が必要なユースケースには不適合だ。マルチリージョン書き込みが必須の場合は DynamoDB Global Tables (Last Writer Wins) を検討する。
AWS Backup と Native Backup を二重管理する: AWS Backup を導入した後も Native の自動バックアップをそのままにすると、コストが重複する。AWS Backup に統合管理を委ねた場合は、Native バックアップの保持期間を最小化する。
DynamoDB Streams の Lambda Trigger でバッチ処理を代用する: Streams の Lambda Trigger はリアルタイムイベント駆動向けだ。夜間バッチ集計には DynamoDB Exports to S3 + Athena の組み合わせが適切だ。Streams でバッチ量を流すと Lambda Concurrency を圧迫し、他のリアルタイム連携が遅延する。
DMS Replication Instance を開発・本番で共用する: 開発の移行テストと本番の本番移行を同一 Replication Instance で実行すると、開発タスクがリソースを消費して本番移行に遅延が発生するリスクがある。本番移行専用の Replication Instance を用意し、IaC (Terraform) で本番移行期間中のみ起動・削除するコスト最適化パターンを採用する。
Aurora Global の Secondary をアクティブ書き込みとして使用する: Aurora Global の Secondary は Read-only だ。Write Forwarding を有効化すると Secondary への書き込みが Primary に転送されるが、転送レイテンシが発生し、Primary 障害時に転送中のトランザクションが失われる可能性がある。本番では Secondary を Headless (Read-only Endpoint のみ) として運用し、Write Forwarding は低遅延許容ユースケース限定で適用する。
Terraform 実装例: AWS Backup Plan (DynamoDB + RDS 統合)
以下は AWS Backup で DynamoDB と RDS を統合管理するための Terraform 実装例だ。BackupRequired = true タグが付与されたリソースを自動的にバックアップ対象に追加し、Cross-Region Copy で DR リージョンの Vault にコピーする。
resource "aws_backup_vault" "production" {
name = "production-backup-vault"
kms_key_arn = aws_kms_key.backup.arn
tags = {
Environment = "production"
Compliance = "required"
}
}
resource "aws_backup_vault_lock_configuration" "production" {
backup_vault_name= aws_backup_vault.production.name
changeable_for_days = 3
max_retention_days = 2555
min_retention_days = 7
}
resource "aws_backup_plan" "unified" {
name = "unified-database-backup-plan"
rule {
rule_name= "daily-backup"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 3 * * ? *)"
start_window= 60
completion_window = 180
lifecycle {
cold_storage_after = 30
delete_after = 365
}
copy_action {
destination_vault_arn = aws_backup_vault.dr_region.arn
lifecycle {
cold_storage_after = 30
delete_after = 365
}
}
}
rule {
rule_name= "weekly-full"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 2 ? * SUN *)"
start_window= 60
completion_window = 480
lifecycle {
cold_storage_after = 90
delete_after = 2555
}
}
}
resource "aws_backup_selection" "databases" {
name= "all-databases"
iam_role_arn = aws_iam_role.backup.arn
plan_id= aws_backup_plan.unified.id
selection_tag {
type = "STRINGEQUALS"
key= "BackupRequired"
value = "true"
}
}
changeable_for_days = 3 が Vault Lock の Cooling-off Period だ。この期間中は Lock 設定を変更・削除できるが、経過後は Compliance Mode が確定し、保持期間内のバックアップは削除不可になる。本番適用前は必ず changeable_for_days を長めに設定し、Governance Mode で動作を検証する。
設計のポイント
min_retention_days = 7 / max_retention_days = 2555 (7年) の範囲設定は、Backup Plan の rule 内 lifecycle.delete_after が必ずこの範囲内に収まるよう強制する。範囲外の設定は Terraform Apply 時にエラーになるため、コードレビューで気付けない設定ミスを Vault Lock 側で防ぐ二重保護の役割も果たす。
copy_action ブロックで指定する destination_vault_arn は DR リージョン (例: ap-northeast-3 大阪) に事前作成した Vault を参照する。DR リージョンの Vault にも同様の Vault Lock を適用し、Primary リージョン障害時にも削除不可 WORM 保護が維持されるよう設計する。
運用上の注意点
selection_tag の BackupRequired = true は、新規リソース追加時に Tag 付けを忘れると自動的にバックアップ対象から漏れる。Tag 付け漏れを防ぐため、AWS Config の Required Tag ルールで Tag 必須強制と自動修復を組み合わせることを推奨する。この Config ルール設計はセキュリティ・コスト管理軸で学んだ Config Conformance Pack の実践的応用だ。
- DMS は移行ツール、DR ツールではない: 継続 DR レプリカとして DMS を長期運用するとコストが高く、Replication Instance の運用負荷も増大する。本番 DR には Aurora Global / DynamoDB Global Tables を使う。
- Aurora Global の Secondary は書き込み不可 (Write Forwarding を除く): Primary 障害時の Promote 前に Secondary に直接書き込もうとするとエラーになる。Failover Runbook に Promote 前後のアプリケーション接続切替手順を明記する。
- DynamoDB Streams の保持期間は 24 時間: Lambda が停止・遅延すると古いレコードが期限切れで読み取れなくなる。Iterator Age アラートを設定し、24 時間を超える前に処理遅延を検知する。
- Vault Lock Compliance Mode は解除不可: Cooling-off Period (最大 72 時間) 経過後は設定変更・削除が不可能になる。本番適用前に Governance Mode で十分な動作検証を実施する。
- Cross-Region Snapshot の転送コスト: Cross-Region Copy は転送量 × リージョン間転送料金が発生する。月次 Full + 日次 Incremental の組み合わせで転送量を最小化し、Cold Storage 移行で長期保存コストを最適化する。
- DMS (Database Migration Service): Replication Instance + Endpoint + Task。Full Load + CDC で異種DB間移行・継続Replication対応。Schema Conversion Tool (SCT) で異種DB スキーマ変換。
- Aurora Global Database: Primary Region + Secondary Region (最大5)。1秒以内 Replication Lag。Headless DR で Secondary Reader 専用構成。Failover 30〜60秒。
- DynamoDB Streams + Global Tables: 24時間保持 Stream + Lambda Trigger + Kinesis連携。Global Tables で Multi-Region 双方向 Replication。Last Writer Wins の Conflict 解決。
- AWS Backup: 統合バックアップ管理 (RDS/Aurora/DynamoDB/EFS/EBS等)。Backup Plan + Vault + Lifecycle Policy + Cross-Account/Cross-Region。Vault Lock で WORM (Write Once Read Many) 保護。
- Q1: 異種DB間移行 (Oracle→Aurora 等) か? Yes → DMS / No → 次へ
- Q2: Multi-Region 配置が必要か? Yes → Aurora Global or DynamoDB Global Tables / No → 次へ
- Q3: CDC (変更データキャプチャ) を下流連携するか? Yes → DynamoDB Streams or DMS CDC / No → 次へ
- Q4: 統合バックアップ管理 (複数DB/EFS/EBS) が必要か? Yes → AWS Backup / No → 各サービス Native Backup
- Q5: コンプライアンス要件 (WORM保管・暗号化) は必須か? Yes → AWS Backup Vault Lock / No → Native Snapshot
3. DMS本番運用 ★山場1
3-1. Replication Instance 設計 — Multi-AZ / スペック選定 / VPC 配置
DMS の移行作業の中核を担う Replication Instance は、Source と Target の中間でデータを一時保持しながら変換・転送を行うインスタンス群です。本番環境では以下の3点を考慮して設計します。
インスタンスクラス選定
| ユースケース | 推奨クラス | 理由 |
|---|---|---|
| 開発・PoC | dms.t3.medium | 低コスト・小規模テスト向け |
| 本番 Full Load | dms.c5.xlarge〜4xlarge | CPU バインドの行変換処理に最適 |
| LOB 列含む本番移行 | dms.r6i.xlarge〜4xlarge | LOB バッファをメモリに確保 |
| CDC 継続 Replication | dms.c5.xlarge | ネットワーク I/O バランス型 |
Multi-AZ 構成の必要性
本番では MultiAZ: true を必ず設定します。Replication Instance のプライマリ障害時に自動フェイルオーバーが行われ、CDC ストリームの中断を最小化します。フェイルオーバー所要時間は 60〜120 秒程度のため、Source の binlog / redo log 保持期間がこれをカバーできる設定 (最低 24 時間) にしておきます。
VPC / セキュリティグループ配置
Replication Instance は Source と Target の両エンドポイントに到達できるサブネット (Replication Subnet Group) に配置します。本番では PubliclyAccessible: false を設定し、Source / Target への接続は VPC 内経路またはサービスエンドポイント経由に限定します。
3-2. Endpoint 設定 — Source / Target / IAM / SSL
Source Endpoint と Target Endpoint にはそれぞれ接続情報とエンジン種別 (mysql / postgres / oracle 等) を設定します。
IAM Role の権限分離
DMS は Source には読み取り専用ロール、Target には書き込み専用ロールを使用します。Source DB には REPLICATION CLIENT / REPLICATION SLAVE (MySQL 系) または LogMiner 権限 (Oracle 系) が必要です。
SSL 設定と接続テスト
Endpoint の ssl_mode は本番では require または verify-full を使用します。Aurora の場合は RDS CA 証明書バンドルを利用します。エンドポイント作成後は必ず「接続テスト」を実行し successful を確認してからタスクを作成します。接続テストが通らない状態でタスクを実行しても即座に失敗します。
3-3. Task 種類と使い分け — Full Load + CDC が本番推奨
DMS タスクには3種類の移行モードがあります。
| モード | 用途 | Cutover タイミング |
|---|---|---|
| Full Load only | 一時スナップショット移行・分析用コピー | Full Load 完了後即 Cutover |
| CDC only | 既存移行済みデータへの変更差分追従 | 既に Full Load 済み状態から開始 |
| Full Load + CDC | 本番推奨: 初回全件 + 継続差分同期 | CDC ラグが安定後に Cutover |
本番移行では「Full Load + CDC」を選択し、Full Load 完了後もアプリが旧 DB に書き込みを続けながら DMS が差分を同期する「並走期間」を設けます。CDC のラグが 1 秒以内で安定した状態で Cutover を実施します。
sequenceDiagram
participant Source as Source DB
participant DMS as DMS Replication Instance
participant Target as Target DB
participant OPS as 運用チーム
OPS->>DMS: Task 開始 (Full Load + CDC)
DMS->>Source: スナップショット取得開始
DMS->>Target: Full Load 転送 (全件コピー)
Note over DMS,Target: Full Load 完了 → CDC フェーズへ移行
loop CDC フェーズ (並走期間)
Source->>DMS: binlog / redo log ストリーム
DMS->>Target: 変更差分を適用
end
OPS->>DMS: CDCLatencyTarget 確認 (1 秒以内)
OPS->>OPS: Cutover 判断 (差分件数 0 確認)
OPS->>DMS: Task 停止
OPS->>Target: Application 接続切替完了
3-4. Schema Conversion Tool (SCT) — 異種 DB 移行のスキーマ変換
異種 DB 間移行 (Oracle → Aurora PostgreSQL / SQL Server → Aurora MySQL 等) では SCT を使用してスキーマを自動変換します。
SCT の作業フロー
- SCT で Source DB に接続し「Schema Conversion Report」を生成
- 自動変換可能な割合 (通常 70〜95%) と「Action Required」アイテムを確認
- Action Required アイテムは手動でスクリプト修正 (ストアドプロシージャ・パッケージ・ROWID 依存処理等)
- 変換スクリプトを Target DB に適用し動作確認
- DMS タスクで Full Load + CDC を実行
SCT のアンチパターン
SCT が生成した DDL スクリプトをレビューせずに Target に適用すると、Oracle の ROWID 依存ビューや SQL Server の IDENTITY カラムが正しく変換されず、Full Load 後のデータ整合性が崩れます。Schema Action Report の全項目 (NotConvertedItems) を確認することが必須です。
3-5. LOB 制限対応 — Limited LOB Mode vs Full LOB Mode
LOB (Large Object) 列 (CLOB / BLOB / TEXT / BYTEA 等) を含むテーブルの移行では、LOB ハンドリングモードの選択がパフォーマンスと安定性に直結します。
| モード | 動作 | 用途 |
|---|---|---|
| Limited LOB | LobMaxSize (KB) 以下の LOB をインライン転送 | 本番推奨: 大多数の LOB が閾値以内の場合 |
| Full LOB | 全 LOB を個別 SELECT で再フェッチ | LOB サイズが不定で LobMaxSize 設定困難な場合 |
| Inline LOB | Full Load 時のみ LOB をインラインで転送 | 小サイズ LOB のみを高速転送する場合 |
Limited LOB Mode の閾値設定指針
LOB カラムの実際のサイズ分布を Source DB で事前に計測し、95 パーセンタイル値を LobMaxSize に設定します。LobMaxSize を超える行は切り捨てが発生するため、超過行は別 Task で Full LOB 処理として分離移行します。
-- Oracle: LOB サイズ分布の事前計測
SELECT
ROUND(DBMS_LOB.GETLENGTH(lob_column) / 1024) AS size_kb,
COUNT(*) AS cnt
FROM source_table
GROUP BY ROUND(DBMS_LOB.GETLENGTH(lob_column) / 1024)
ORDER BY size_kb DESC
FETCH FIRST 20 ROWS ONLY;
- 原則1: 本番移行は dms.c5.xlarge 以上 + Multi-AZ Replication Instance
- 原則2: Full Load 完了後 CDC モードに切替・Cutover ウィンドウは最小化
- 原則3: LOB 列は Limited LOB + LobMaxSize 設定で性能とデータ完整性を両立
- 原則4: Validation 有効化で Source/Target 差分検出を本番投入前に実施
- 原則5: SCT で生成したスキーマは必ず Schema Action Report を確認し手動修正
Full LOB モードは全 LOB 列を SELECT で再帰的にフェッチしてバッファリングするため、LOB 数が多いテーブルで Replication Instance のメモリが枯渇し、移行タスクが強制停止します。本番では Limited LOB + LobMaxSize を必ず設定してください。LobMaxSize はデフォルト 32 KB が多く、実際の LOB サイズを計測せずに適用すると切り捨てが発生します。設定手順: (1) Source の LOB サイズ分布を事前計測 → (2) 95 パーセンタイル値を LobMaxSize に設定 → (3) 超過行を別 Task で Full LOB 処理として分離移行。
3-6. Validation 設定 — 差分検出 / 不整合検知
DMS の Table Validation 機能を有効にすると、Full Load 完了後に Source と Target のレコード数・チェックサムを比較し、差分件数を CloudWatch メトリクスとして記録します。本番移行前の品質ゲートとして必ず使用します。
検証エラーの対応フロー
- CloudWatch メトリクス
ValidationSuspendedRecords/ValidationFailedRecordsを監視 - 差分件数が閾値 (例: 0 件) を超えた場合は移行タスクを一時停止
aws dms describe-table-statisticsで不整合検知テーブルを特定- 対象テーブルを部分 Reload (Table Reload) して差分を解消
- 差分件数 0 を確認後、Cutover を実施
3-7. CDC 性能監視 — Replication Lag / CloudWatch メトリクス
CDC フェーズでの継続 Replication 安定性は以下のメトリクスで監視します。
| メトリクス | 説明 | 警告閾値 |
|---|---|---|
CDCLatencySource | Source から DMS への binlog 取得遅延 | 30 秒超過 |
CDCLatencyTarget | DMS から Target への変更差分適用遅延 | 30 秒超過 |
CDCIncomingChanges | Source から受信した変更イベント数/秒 | 上限目安として監視 |
CDCThroughputRowsTarget | Target への適用行数/秒 | 下限目安として監視 |
CDCLatencyTarget が継続的に増加している場合、Replication Instance の CPU/ネットワーク帯域が飽和しているか、Target DB の書き込みスループットが不足しています。対策: (1) Replication Instance を上位クラスにスケールアップ (c5.xlarge → c5.2xlarge 等) → (2) Target の書き込み IOPS を増強 (Aurora の場合は Writer インスタンスクラス変更) → (3) Source の binlog 保持時間を最低 24 時間に延長してラグ吸収余地を確保。CDCLatencyTarget が 1 秒以内で安定するまで Cutover を延期することが原則です。
Terraform 実装例 — DMS 3要素
aws_dms_replication_instance (本番 Multi-AZ)
resource "aws_dms_replication_subnet_group" "main" {
replication_subnet_group_id = "prod-dms-subnet-group"
replication_subnet_group_description = "DMS Replication Subnet Group for production"
subnet_ids= var.private_subnet_ids
}
resource "aws_dms_replication_instance" "prod" {
replication_instance_id = "prod-dms-ri"
replication_instance_class = "dms.c5.xlarge"
allocated_storage = 100
multi_az = true
publicly_accessible= false
replication_subnet_group_id = aws_dms_replication_subnet_group.main.id
vpc_security_group_ids= [aws_security_group.dms.id]
engine_version = "3.5.2"
auto_minor_version_upgrade = true
tags = {
Environment = "production"
Project = "db-migration"
}
}
aws_dms_endpoint (Source Oracle / Target Aurora PostgreSQL)
resource "aws_dms_endpoint" "source_oracle" {
endpoint_id= "prod-source-oracle"
endpoint_type = "source"
engine_name= "oracle"
server_name= var.oracle_host
port = 1521
database_name = var.oracle_db
username= var.oracle_user
password= var.oracle_password
ssl_mode= "require"
oracle_settings {
use_logminer_reader = true
standby_delay_time = 0
}
tags = { Environment = "production" }
}
resource "aws_dms_endpoint" "target_aurora_pg" {
endpoint_id= "prod-target-aurora-pg"
endpoint_type = "target"
engine_name= "aurora-postgresql"
server_name= aws_rds_cluster.aurora.endpoint
port = 5432
database_name = var.target_db
username= var.target_user
password= var.target_password
ssl_mode= "require"
tags = { Environment = "production" }
}
aws_dms_replication_task (Full Load + CDC / Validation 有効)
resource "aws_dms_replication_task" "full_load_cdc" {
replication_task_id= "prod-migration-full-load-cdc"
migration_type = "full-load-and-cdc"
replication_instance_arn = aws_dms_replication_instance.prod.replication_instance_arn
source_endpoint_arn= aws_dms_endpoint.source_oracle.endpoint_arn
target_endpoint_arn= aws_dms_endpoint.target_aurora_pg.endpoint_arn
table_mappings = jsonencode({
rules = [{
rule-type = "selection"
rule-id= "1"
rule-name = "include-all"
object-locator = {
schema-name = var.source_schema
table-name = "%"
}
rule-action = "include"
}]
})
replication_task_settings = jsonencode({
TargetMetadata = {
SupportLobs = true
FullLobMode = false
LimitedSizeLobMode = true
LobMaxSize= 32
}
FullLoadSettings = {
TargetTablePrepMode = "DROP_AND_CREATE"
}
ValidationSettings = {
EnableValidation = true
ValidationMode= "ROW_LEVEL"
ThreadCount= 5
PartitionSize = 10000
}
Logging = {
EnableLogging = true
}
})
tags = {
Environment= "production"
MigrationType = "full-load-cdc"
}
}
---
## 4. Aurora Global Database本番運用 ★山場2
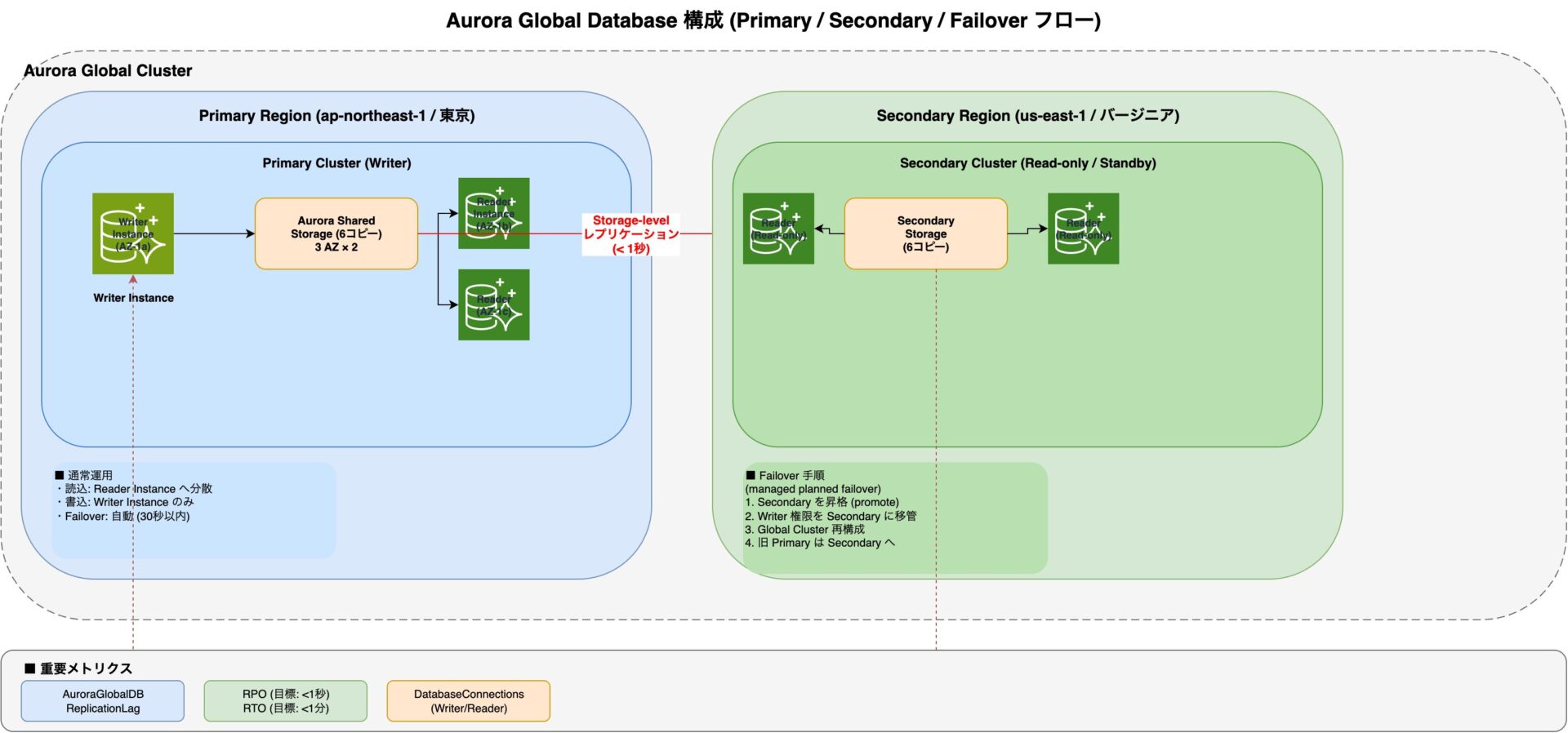
Aurora Global Database は Primary Region 1つと Secondary Region 最大5つで構成されるクロスリージョン分散 Aurora クラスタです。ストレージレイヤーを介した専用レプリケーションにより **1秒以内**の Replication Lag を実現し、Primary Region 全域障害時に Secondary を数十秒で Promote できる **Headless DR** 設計が本番運用の核心です。
> **Aurora の Backup/Restore/DR 詳細**(ポイントインタイムリカバリ・Cross-Region Snapshot・IAM Database Authentication)は [Aurora Backup/Restore/DR シリーズ](https://www.watchittrend.com/aurora-backup-restore-dr-s1/) および [Aurora No-Human Login](https://www.watchittrend.com/aurora-no-human-login/) を参照してください。本 §4 は **Aurora Global Database 固有のグローバル展開・Failover・Failback 運用**に集中します。
### 4-1. Global Cluster 構成設計
Aurora Global Cluster は **Global Cluster → Primary DB Cluster → Secondary DB Cluster(s)** の3層構造です。
| レイヤー | リソース | 役割 |
|---------|---------|------|
| Global Cluster | `aws_rds_global_cluster` | リージョン間レプリケーションの束 |
| Primary Cluster | `aws_rds_cluster` (書き込み受付) | 全 DML を受け付ける主 Cluster |
| Secondary Cluster | `aws_rds_cluster` (読み取り専用) | DR 待機・Read オフロード |
Secondary Cluster を Reader 専用で運用する **Headless DR 構成**が推奨です。Secondary への Read ルーティングにより Replication Lag を実用的に監視できます。
```hcl
resource "aws_rds_global_cluster" "main" {
global_cluster_identifier = "global-aurora-prod"
engine = "aurora-postgresql"
engine_version= "15.4"
database_name = "proddb"
storage_encrypted= true
}
resource "aws_rds_cluster" "primary" {
cluster_identifier = "aurora-primary-prod"
engine = "aurora-postgresql"
engine_version= "15.4"
global_cluster_identifier = aws_rds_global_cluster.main.id
master_username = var.db_username
master_password = var.db_password
db_subnet_group_name= aws_db_subnet_group.primary.name
vpc_security_group_ids = [aws_security_group.aurora_primary.id]
backup_retention_period= 7
deletion_protection = true
storage_encrypted= true
kms_key_id = aws_kms_key.aurora.arn
tags = { Env = "prod", Role = "global-primary" }
}
resource "aws_rds_cluster" "secondary" {
provider = aws.osaka
cluster_identifier = "aurora-secondary-osaka"
engine = "aurora-postgresql"
engine_version= "15.4"
global_cluster_identifier = aws_rds_global_cluster.main.id
db_subnet_group_name= aws_db_subnet_group.secondary.name
vpc_security_group_ids = [aws_security_group.aurora_secondary.id]
storage_encrypted= true
kms_key_id = aws_kms_key.aurora_osaka.arn
tags = { Env = "prod", Role = "global-secondary" }
}
4-2. 1秒以内レプリケーションの仕組みと監視
Aurora Global の Replication はアプリケーションレイヤーではなくストレージレイヤーで行われます。Primary の redo log をストレージノード間で直接転送するため通常の DB レプリケーションより大幅に低遅延です。AuroraGlobalDBReplicationLag (CloudWatch) でミリ秒単位の Lag を監視します。
| 閾値 | レベル | 対応 |
|---|---|---|
| 1,000 ms 超過 | Warning | Primary 書き込みレート・ネットワーク帯域確認 |
| 5,000 ms 超過 | Critical | 書き込みレート抑制・Secondary 状態確認 |
| 60,000 ms 超過 | Emergency | 手動 Failover 検討・Primary 停止疑い |
resource "aws_cloudwatch_metric_alarm" "global_lag_critical" {
alarm_name = "aurora-global-lag-critical"
namespace = "AWS/RDS"
metric_name= "AuroraGlobalDBReplicationLag"
statistic = "Maximum"
period = 60
evaluation_periods = 2
threshold = 5000
comparison_operator = "GreaterThanThreshold"
alarm_actions = [aws_sns_topic.alerts.arn]
dimensions = {
DBClusterIdentifier = aws_rds_cluster.secondary.cluster_identifier
}
}
4-3. Headless DR 設計パターン
Headless DR は Secondary Cluster を常時 Active-Standby 状態で維持し、Primary 停止時に即座に Promote できる構成です。”Headless” は Secondary に Writer インスタンスを持たない状態を指します。
Primary (ap-northeast-1)Secondary (ap-northeast-3)
┌────────────────────────┐ ┌────────────────────────┐
│ Writer Instance │──→────│ [No Writer / Standby] │
│ Reader Instance ×2 │ │ Reader Instance ×1 │
│ ↑ 全書き込み受付 │ │ ↑ Read オフロード専用 │
└────────────────────────┘ └────────────────────────┘
↓ Global Replication (ストレージレイヤー / <1秒)
設計のポイント:
– Application の接続先を ClusterEndpoint (Primary) と ReaderEndpoint (Secondary) で分離
– Failover 後の Endpoint 切替は Route 53 CNAME または Parameter Store で抽象化
– Secondary Reader への分析系・レポート処理ルーティングで Replication Lag を実用監視
4-4. 計画 Failover 手順 (Managed Planned Failover)
計画 Failover は AWS Console / CLI から事前に制御できる手順です。Managed Planned Failover は Secondary に全 redo log を適用してから切り替えるため RPO = 0 を実現します。
計画 Failover 手順書:
# Step1: Managed Planned Failover を実行
aws rds failover-global-cluster \
--global-cluster-identifier global-aurora-prod \
--target-db-cluster-identifier \
arn:aws:rds:ap-northeast-3:123456789012:cluster:aurora-secondary-osaka \
--region ap-northeast-1
# Step2: Failover 完了確認 (通常 30〜60秒)
aws rds describe-global-clusters \
--global-cluster-identifier global-aurora-prod \
--query 'GlobalClusters[0].GlobalClusterMembers[*].{ARN:DBClusterArn,Writer:IsWriter}'
# Step3: Application の Endpoint を新 Primary (旧 Secondary) に切り替え
# Route 53 CNAME または Parameter Store の Endpoint 値を更新
所要時間の目安:
| フェーズ | 時間 |
|---|---|
| Managed Planned Failover 実行 | 30〜60秒 |
| Application Endpoint 切替 | 1〜3分 |
| 合計 RTO | 5分以内 |
| RPO | 0 (全 redo log 適用後に切替) |
4-5. 非計画 Failover 手順 (Detach & Promote)
Primary Region が全域停止した場合、Managed Planned Failover は使用できません。Detach & Promote で Secondary を独立した Primary として昇格させます。
非計画 Failover 手順書:
# Step1: Secondary を Global Cluster から切り離す (Detach)
aws rds remove-from-global-cluster \
--db-cluster-identifier \
arn:aws:rds:ap-northeast-3:123456789012:cluster:aurora-secondary-osaka \
--global-cluster-identifier global-aurora-prod \
--region ap-northeast-3
# Step2: Detached Cluster が Writer を保有するまで待機 (30〜120秒)
aws rds describe-db-clusters \
--db-cluster-identifier aurora-secondary-osaka \
--region ap-northeast-3 \
--query 'DBClusters[0].{Status:Status}'
# Step3: Application を新 Primary (ap-northeast-3) に接続切替
# Step4: 旧 Primary 復旧後 → §4-6 Failback 手順へ
RTO/RPO 試算:
| 項目 | 値 |
|---|---|
| Detach & Promote 操作 | 30〜120秒 |
| Application Endpoint 切替 | 1〜5分 |
| 合計 RTO | 5〜10分 |
| RPO | 最大 1秒 (切替直前の Replication Lag 値に依存) |
4-6. Failback 手順 (旧 Primary を Secondary として再結合)
非計画 Failover 後、旧 Primary Region が復旧した際に元の構成に戻す手順です。Replication Catch-up が完了する前に Failback を実施するとデータ乖離が発生します。最低 24時間の Catch-up 期間を必ず確保してください。
Failback 手順書:
# Step1: 旧 Primary Cluster の復旧状態確認
aws rds describe-db-clusters \
--db-cluster-identifier aurora-primary-prod \
--region ap-northeast-1 \
--query 'DBClusters[0].{Status:Status,DBClusterArn:DBClusterArn}'
# Step2: 旧 Primary を新 Global Cluster の Secondary として追加
# AWS Console: RDS > Global databases > Add region で旧 Cluster をアタッチ
# → 旧 Primary が Replication Catch-up を開始
# Step3: Replication Lag が 0 に収束するまで待機 (最低 24時間)
aws cloudwatch get-metric-statistics \
--namespace AWS/RDS \
--metric-name AuroraGlobalDBReplicationLag \
--dimensions Name=DBClusterIdentifier,Value=aurora-primary-prod \
--start-time "$(date -u -v-30M +%Y-%m-%dT%H:%M:%SZ)" \
--end-time "$(date -u +%Y-%m-%dT%H:%M:%SZ)" \
--period 60 --statistics Maximum
# Step4: Lag 収束 + 30分安定確認後、Managed Planned Failover で元 Region に復帰
aws rds failover-global-cluster \
--global-cluster-identifier global-aurora-prod \
--target-db-cluster-identifier \
arn:aws:rds:ap-northeast-1:123456789012:cluster:aurora-primary-prod \
--region ap-northeast-3
# Step5: Application Endpoint を元の Primary (ap-northeast-1) に戻す
Failback 実施前チェックリスト:
– [ ] 旧 Primary Region のインフラ (VPC/Subnet/Security Group) が正常復旧済み
– [ ] AuroraGlobalDBReplicationLag が 1秒以内で最低 30分安定
– [ ] 最低 24時間の Replication Catch-up 期間を経過済み
– [ ] Application Endpoint 切替後の動作確認手順が準備済み
– [ ] 四半期 Failover Drill の記録から RTO を更新済み
4-7. Aurora Global Failover シーケンス (mermaid02)
sequenceDiagram
participant App as Application
participant P as Primary Cluster<br/>(ap-northeast-1)
participant G as Global Cluster
participant S as Secondary Cluster<br/>(ap-northeast-3)
participant Ops as 運用チーム
Note over P: Primary 停止検知
P->>Ops: CloudWatch Alarm<br/>(Replication Lag / DB unreachable)
Ops->>Ops: Failover 手順書確認<br/>非計画 Failover と判断
Ops->>G: remove-from-global-cluster<br/>(Detach Secondary)
G->>S: Promote 開始
S-->>Ops: Status: available<br/>(30〜120秒)
Ops->>App: Endpoint 切替指示<br/>(Route 53 / Parameter Store 更新)
App->>S: 新 Primary へ接続開始
Note over S: 新 Primary として稼働<br/>RTO: 5〜10分
Note over P: 復旧後 → Failback 手順へ<br/>(最低 24時間後)
- 原則1: Secondary Region は最低2つ (Multi-DR / Active-Passive)
- 原則2: Replication Lag アラート閾値は 1秒超過で Warning / 5秒超過で Critical
- 原則3: Failover Drill は四半期1回必須 (本番同等手順で RTO 計測)
- 原則4: Failback は最低 24時間の Replication Catch-up 期間を確保
- 原則5: Write Forwarding は遅延許容ユースケース限定で適用
非計画 Failover 後に旧 Primary Region が復旧すると、Application が誤って旧 Primary に書き込みを再開するケースがある。この状態では新 Primary と旧 Primary の間でデータが乖離し、どちらが正となのか判断できなくなる。Failover 手順書には「旧 Primary 復旧後は必ず読み取り専用モードで起動し Failback 完了まで書き込みを禁止する」を明記し、Application の Endpoint 設定を Route 53 / Parameter Store で一元管理する。
AuroraGlobalDBReplicationLag が 1秒を超えると Secondary の Read 整合性が低下し、Failover 時の RPO も悪化する。Lag 増大の主因は Primary の書き込みバースト・Secondary Region のネットワーク帯域逼迫・Secondary インスタンスのスペック不足の3つ。監視では Maximum 統計を 60秒周期で取得し Warning (1秒超過) → Critical (5秒超過) の2段階アラームを設定する。Critical 発生時は Primary の書き込みレートを抑制し、Secondary インスタンスクラスの増強を検討する。
5. DynamoDB Streams + Global Tables本番運用 ★山場3
DynamoDB Streams は DynamoDB テーブルへの変更を時系列ストリームとして出力するマネージドサービスであり、Lambda Trigger と組み合わせることで CDC (Change Data Capture) パターンを実現する。本章では StreamViewType 選定から Lambda Trigger の本番設計・Iterator Age 監視・Kinesis Data Streams 連携・Global Tables の Conflict 解決・TTL 連携まで、本番運用に必須な実装パターンを体系的に解説する。
5.1 StreamViewType 4種類詳解
DynamoDB Streams は StreamViewType の設定で Stream レコードに含まれる情報量を制御する。一度有効化したテーブルは無停止で変更可能だが、設定変更は後続 Lambda に即時反映されるため本番変更時はロールバック手順を事前確認すること。
| StreamViewType | 含まれる情報 | 主なユースケース | サイズ |
|---|---|---|---|
| KEYS_ONLY | 主キー (PK/SK) のみ | 変更通知・キャッシュ無効化 | 最小 |
| NEW_IMAGE | 変更後のアイテム全体 | 下流レプリケーション・Elasticsearch 同期 | 中 |
| OLD_IMAGE | 変更前のアイテム全体 | 削除前データ保全・監査ログ | 中 |
| NEW_AND_OLD_IMAGES | 変更前後のアイテム全体 | 差分計算・変更ログ・詳細監査 | 最大 |
本番推奨: NEW_AND_OLD_IMAGES
変更前後の両イメージを保持することで Lambda 側で「何が変わったか」を計算できる。ストレージサイズは最大になるが、後からの再処理や監査要件がある場合は必須。ユースケースが KEYS_ONLY で十分(キャッシュ無効化のみ等)な場合のみ最小構成を選択する。
resource "aws_dynamodb_table" "orders" {
name = "orders"
billing_mode= "PAY_PER_REQUEST"
hash_key = "order_id"
range_key= "created_at"
attribute {
name = "order_id"
type = "S"
}
attribute {
name = "created_at"
type = "S"
}
stream_enabled= true
stream_view_type = "NEW_AND_OLD_IMAGES"
ttl {
attribute_name = "expire_at"
enabled = true
}
server_side_encryption {
enabled = true
}
tags = {
Environment = "production"
ManagedBy= "terraform"
}
}
5.2 Lambda Trigger 設計 — event source mapping 本番パラメータ
DynamoDB Streams と Lambda を接続する event source mapping (ESM) は複数のパラメータで処理挙動を制御する。デフォルト設定のまま本番投入すると Iterator Age 増大・処理失敗の連鎖が起きる。
| パラメータ | 推奨値 | 説明 |
|---|---|---|
| batch_size | 10〜100 | 1回の Lambda 起動に含めるレコード数。大きいほど効率的だが失敗時の影響範囲も拡大 |
| maximum_retry_attempts | 3 | 一時的障害のリトライ上限。-1 (無制限) は本番禁止 |
| bisect_batch_on_function_error | true | 失敗時にバッチを半分に分割して再試行。毒データの切り分けに有効 |
| parallelization_factor | 1〜10 | 1 Shard に対して並列起動する Lambda 数。デフォルト1、最大10 |
| destination_config (on_failure) | SQS DLQ | 最大リトライ後も失敗したレコードを SQS Dead Letter Queue に転送 |
| maximum_record_age_in_seconds | 86400 | 24時間以内のレコードのみ処理(Stream 保持期間に合わせる) |
| starting_position | LATEST | 新規 ESM は LATEST。既存データ遡及が必要な場合のみ TRIM_HORIZON |
resource "aws_lambda_event_source_mapping" "orders_stream" {
event_source_arn = aws_dynamodb_table.orders.stream_arn
function_name = aws_lambda_function.orders_processor.arn
starting_position = "LATEST"
batch_size= 50
maximum_retry_attempts= 3
bisect_batch_on_function_error = true
parallelization_factor= 5
maximum_record_age_in_seconds = 86400
destination_config {
on_failure {
destination_arn = aws_sqs_queue.orders_dlq.arn
}
}
filter_criteria {
filter {
pattern = jsonencode({
eventName = ["INSERT", "MODIFY"]
})
}
}
}
resource "aws_sqs_queue" "orders_dlq" {
name = "orders-stream-dlq"
message_retention_seconds = 1209600
kms_master_key_id= "alias/aws/sqs"
}
Lambda ハンドラー本番パターン (try/except)
import boto3
from boto3.dynamodb.types import TypeDeserializer
deserializer = TypeDeserializer()
def lambda_handler(event, context):
processed = 0
failed_ids = []
for record in event["Records"]:
try:
event_name = record["eventName"]
ddb = record.get("dynamodb", {})
new_item = {k: deserializer.deserialize(v) for k, v in ddb.get("NewImage", {}).items()}
old_item = {k: deserializer.deserialize(v) for k, v in ddb.get("OldImage", {}).items()}
if event_name == "INSERT":
handle_insert(new_item)
elif event_name == "MODIFY":
handle_modify(new_item, old_item)
elif event_name == "REMOVE":
handle_remove(record, old_item)
processed += 1
except Exception as e:
print(f"Failed record={record['eventID']} error={e}")
failed_ids.append(record["eventID"])
if failed_ids:
raise Exception(f"Failed {len(failed_ids)} records: {failed_ids}")
print(f"Processed {processed} records")
return {"processed": processed}
def handle_insert(item):
pass
def handle_modify(new_item, old_item):
changed = {k for k in new_item if new_item.get(k) != old_item.get(k)}
print(f"Changed fields: {changed}")
def handle_remove(record, old_item):
user_identity = record.get("userIdentity", {})
is_ttl = (
user_identity.get("type") == "Service"
and user_identity.get("principalId") == "dynamodb.amazonaws.com"
)
if is_ttl:
handle_ttl_expiry(old_item)
else:
handle_explicit_delete(old_item)
def handle_ttl_expiry(item):
print(f"TTL expired: {item}")
def handle_explicit_delete(item):
print(f"Explicit delete: {item}")
5.3 Iterator Age 監視とアラーム設定
IteratorAge は Stream の最新レコードと Lambda が処理中の最古レコードの時間差(ミリ秒)。この値が増加し続ける場合、Lambda の処理能力がレコード発生速度に追いついていないことを示す。
| 原因 | 対策 |
|---|---|
| Lambda 同時実行数が上限に達している | Reserved Concurrency を ESM 専用に確保 |
| Shard 数に対して parallelization_factor が低い | parallelization_factor を段階的に引き上げ (1→3→5→10) |
| Lambda Duration が長い | 処理ロジックの最適化 / バッチ処理化 |
| 下流サービス (RDS 等) のスロットリング | 下流側スループット拡張またはキュー挟み込み |
resource "aws_cloudwatch_metric_alarm" "iterator_age_warning" {
alarm_name = "dynamodb-streams-iterator-age-warning"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = 3
metric_name= "IteratorAge"
namespace = "AWS/Lambda"
period = 300
statistic = "Maximum"
threshold = 300000
dimensions = {
FunctionName = aws_lambda_function.orders_processor.function_name
}
alarm_actions = [aws_sns_topic.alerts.arn]
}
resource "aws_cloudwatch_metric_alarm" "iterator_age_critical" {
alarm_name = "dynamodb-streams-iterator-age-critical"
comparison_operator = "GreaterThanThreshold"
evaluation_periods = 2
metric_name= "IteratorAge"
namespace = "AWS/Lambda"
period = 300
statistic = "Maximum"
threshold = 1800000
dimensions = {
FunctionName = aws_lambda_function.orders_processor.function_name
}
alarm_actions = [aws_sns_topic.alerts_critical.arn]
}
- Step 1: Lambda の ConcurrentExecutions を CloudWatch で確認 — アカウント上限に近い場合は Reserved Concurrency 追加
- Step 2: parallelization_factor を段階的に引き上げ (1→3→5→10)
- Step 3: batch_size を引き上げて 1 回の呼び出しで処理量を増やす
- Step 4: Lambda Duration の P99 を確認 — 処理時間自体が長い場合はロジック最適化
- Step 5: 上記で改善しない場合は Kinesis Data Streams への移行を検討 (保持期間を 7〜365日に拡張可能)
5.4 Kinesis Data Streams 連携パターン (高スループット代替)
DynamoDB Streams は Shard ベースのスループット制限があり、大規模テーブル(数万 WCU 超)では Iterator Age 問題が慢性化する。この場合は Kinesis Data Streams (KDS) を経由させる構成を採用する。
| パターン | 仕組み | 適用場面 |
|---|---|---|
| DynamoDB → KDS 直接連携 | kinesis_stream_specification で KDS にエクスポート | 高スループット・保持期間延長 |
| Kinesis Streams Adapter | DynamoDB Streams を KDS API 互換で読む | 既存 KDS 処理基盤に接続したい場合 |
resource "aws_kinesis_stream" "orders_cdc" {
name = "orders-change-data-capture"
shard_count= 4
retention_period = 168
encryption_type = "KMS"
kms_key_id= "alias/aws/kinesis"
tags = {
Environment = "production"
}
}
resource "aws_dynamodb_kinesis_streaming_destination" "orders" {
stream_arn = aws_kinesis_stream.orders_cdc.arn
table_name = aws_dynamodb_table.orders.name
}
KDS 経由にすることで保持期間を最大 7日間(Extended Retention: 最大 365日)に拡張でき、Stream 保持 24時間問題の根本対策になる。また KDS → Kinesis Data Firehose → S3 の経路で変更ログを長期保管する構成も容易に追加できる。
5.5 Global Tables LWW Conflict 解決パターン
DynamoDB Global Tables は Multi-Region 双方向 Replication を提供するが、同一アイテムへ複数 Region から同時書き込みが発生した場合、Last Writer Wins (LWW) で Conflict を解決する。LWW は「最後に書き込んだ Region の値が勝つ」シンプルなルールだが、アプリケーション側の補強設計が不可欠。
LWW Conflict が発生するシナリオ
Region A (ap-northeast-1): order_id=123, status=PAID(T=100ms)
Region B (us-east-1):order_id=123, status=SHIPPED (T=110ms)
→ Replication 後: status=SHIPPED (Region B の後書きが勝つ)
| パターン | 実装方法 | 適用ユースケース |
|---|---|---|
| Version Attribute | version 番号 + Condition Expression | 楽観的ロック(在庫管理等) |
| Timestamp Attribute | updated_at タイムスタンプ比較で Lambda 補正 | イベントログの順序保証 |
| Single-Writer | 書き込み Region を Primary に集約 | Conflict 完全回避が必要な場合 |
| Idempotency Key | 処理済みキーを保持して重複処理を防ぐ | 決済・在庫の冪等性保証 |
import boto3
from botocore.exceptions import ClientError
dynamodb = boto3.resource("dynamodb", region_name="ap-northeast-1")
table = dynamodb.Table("orders-global")
def update_order_with_version(order_id, new_status, expected_version):
"""
Version Attribute を使った楽観的ロック更新。
Conflict 発生時は ConditionalCheckFailedException が発生。
"""
try:
response = table.update_item(
Key={"order_id": order_id},
UpdateExpression="SET #s = :status, version = :new_ver",
ConditionExpression="version = :expected",
ExpressionAttributeNames={"#s": "status"},
ExpressionAttributeValues={
":status": new_status,
":new_ver": expected_version + 1,
":expected": expected_version,
},
ReturnValues="ALL_NEW",
)
return response["Attributes"]
except ClientError as e:
if e.response["Error"]["Code"] == "ConditionalCheckFailedException":
current = table.get_item(Key={"order_id": order_id})["Item"]
raise ValueError(
f"Version conflict: expected={expected_version}, "
f"actual={current.get('version')}"
)
raise
Global Tables を Multi-Region で運用しながら Conflict 解決を Application 側で実装しないと、決済・在庫・予約などの重要データが無通知で上書きされる。典型症状:「支払い完了後に status が PENDING に戻っている」「在庫が負値になっている」。最低限 Version Attribute + Condition Expression を実装し、ConditionalCheckFailedException を適切にハンドリングすること。Global Tables 採用前に「どの Region で書き込みを受け付けるか」を設計段階で確定させる。
5.6 TTL 削除イベントの Streams 処理
DynamoDB TTL によって削除されたアイテムも Streams に REMOVE イベントとして出力される。通常の DeleteItem API による削除と TTL 削除を区別するには userIdentity フィールドを確認する。
| 注意点 | 詳細 |
|---|---|
| 遅延あり | TTL 期限切れから実際の削除まで最大 48時間の遅延が発生する場合がある |
| 順序保証なし | TTL 削除レコードは通常の REMOVE と混在するため処理順序に依存しない設計が必要 |
| OLD_IMAGE 必須 | 削除前データを Stream で取得するには OLD_IMAGE または NEW_AND_OLD_IMAGES が必要 |
| 大量 TTL 削除 | 一時に大量 TTL 削除が発生すると 24時間内に Stream を消費しきれない → KDS 連携で対処 |
TTL 削除レコードの識別は is_ttl_deletion 関数(5.2 のハンドラー参照)で実装済み。handle_remove 内で TTL 削除と明示削除を分岐し、TTL 削除はアーカイブ処理・監査ログ記録、明示削除はカスケードクリーンアップに振り分ける。
5.7 本番 Terraform 完全構成サマリ
resource "aws_dynamodb_table" "orders_global" {
name = "orders-global"
billing_mode = "PAY_PER_REQUEST"
hash_key= "order_id"
range_key = "created_at"
stream_enabled= true
stream_view_type = "NEW_AND_OLD_IMAGES"
attribute { name = "order_id"type = "S" }
attribute { name = "created_at" type = "S" }
ttl {
attribute_name = "expire_at"
enabled = true
}
replica { region_name = "us-east-1" }
replica { region_name = "eu-west-1" }
server_side_encryption { enabled = true }
tags = {
Environment = "production"
ManagedBy= "terraform"
}
}
resource "aws_lambda_function" "orders_processor" {
function_name= "orders-stream-processor"
role= aws_iam_role.lambda_streams_role.arn
handler= "handler.lambda_handler"
runtime= "python3.12"
timeout= 60
memory_size = 256
reserved_concurrent_executions = 50
filename= data.archive_file.lambda_zip.output_path
source_code_hash = data.archive_file.lambda_zip.output_base64sha256
environment {
variables = {
ENVIRONMENT = "production"
}
}
}
DynamoDB Streams のレコード保持期間は 最大24時間固定 であり拡張不可。Lambda の処理が24時間以上停止した場合(Lambda デプロイ失敗・権限変更によるアクセス拒否等)、その間の変更レコードは永久に失われる。高可用性要件には Kinesis Data Streams(保持最大 7日〜365日)への移行を検討すること。
対策チェックリスト
- Lambda ESM の on_failure DLQ を必ず設定し失敗レコードを保全する
- Iterator Age が 12時間を超えた時点で即エスカレーション (24時間の半分がシグナル)
- 高スループット・高可用性要件では Kinesis Data Streams 直接連携を採用
6. Backup戦略本番運用 ★山場4
AWS Backup は RDS / Aurora / DynamoDB / EBS / EFS など複数の AWS マネージドサービスのバックアップを統合管理するサービスだ。個別サービスの Native Backup(Aurora 自動バックアップ・DynamoDB PITR)と AWS Backup の二重管理になりがちなため、各バックアップの役割を明確に分けた統合設計が不可欠。本章では Backup Plan + Vault + Vault Lock から Aurora Backtrack・PITR・Snapshot Lifecycle・コスト試算まで、本番品質のバックアップ戦略を体系的に解説する。
6.1 AWS Backup 統合設計 — Backup Plan + Vault + Resource Assignment
AWS Backup の主要コンポーネントは「Backup Plan(いつ・何日間保持)」「Backup Vault(保管場所)」「Resource Assignment(対象リソース)」の組み合わせで構成される。タグベースの Resource Assignment を採用すると、新規 DB 追加時にタグを付与するだけでバックアップ対象に自動追加される。
| コンポーネント | 役割 | 本番設計ポイント |
|---|---|---|
| Backup Plan | スケジュール・保持期間・ライフサイクル | 日次+週次+月次の多段設計 |
| Backup Vault | バックアップの保管場所 | KMS暗号化必須 / Cross-Region コピー先 |
| Resource Assignment | バックアップ対象リソース選択 | タグベース一括指定を推奨 |
| Backup Rule | Plan 内の個別バックアップルール | Window 時間帯・Cold Storage 移行設定 |
| Backup Job | 実際のバックアップ実行記録 | 失敗 Job のアラート設定必須 |
resource "aws_backup_vault" "production" {
name = "prod-backup-vault"
kms_key_arn = aws_kms_key.backup.arn
tags = {
Environment = "production"
ManagedBy= "terraform"
}
}
resource "aws_backup_vault" "dr_osaka" {
provider = aws.osaka
name = "prod-backup-vault-dr"
kms_key_arn = aws_kms_key.backup_dr.arn
tags = {
Environment = "production"
Region= "osaka"
}
}
resource "aws_backup_plan" "production" {
name = "prod-database-backup-plan"
rule {
rule_name= "daily-14days"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 18 * * ? *)"
start_window= 60
completion_window = 180
lifecycle {
delete_after = 14
}
copy_action {
destination_vault_arn = aws_backup_vault.dr_osaka.arn
lifecycle {
delete_after = 7
}
}
}
rule {
rule_name= "weekly-90days"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 19 ? * 1 *)"
lifecycle {
cold_storage_after = 30
delete_after = 90
}
}
rule {
rule_name= "monthly-1year"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 20 1 * ? *)"
lifecycle {
cold_storage_after = 90
delete_after = 365
}
}
rule {
rule_name= "yearly-7years"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 21 1 1 ? *)"
lifecycle {
cold_storage_after = 180
delete_after = 2555
}
}
}
resource "aws_backup_selection" "databases" {
iam_role_arn = aws_iam_role.backup.arn
name= "prod-database-selection"
plan_id= aws_backup_plan.production.id
selection_tag {
type = "STRINGEQUALS"
key= "BackupEnabled"
value = "true"
}
}
Backup Job 失敗は EventBridge + SNS でアラート通知する:
resource "aws_cloudwatch_event_rule" "backup_job_failed" {
name = "backup-job-failed"
description = "AWS Backup job failure detection"
event_pattern = jsonencode({
source= ["aws.backup"]
detail-type = ["Backup Job State Change"]
detail = {
state = ["FAILED", "ABORTED"]
}
})
}
resource "aws_cloudwatch_event_target" "backup_alert" {
rule= aws_cloudwatch_event_rule.backup_job_failed.name
target_id = "backup-alert-sns"
arn = aws_sns_topic.alerts.arn
}
6.2 Aurora Backtrack — 72時間以内の短期操作ミス即時復旧
Aurora Backtrack は Aurora MySQL 専用の機能で、最大72時間前の任意時点にクラスターを巻き戻すことができる。Snapshot Restore と異なり、新しいクラスターを起動せず既存クラスターをそのまま巻き戻すため、RTO が数分以内と極めて短い。
| 項目 | 詳細 |
|---|---|
| 対応エンジン | Aurora MySQL のみ(Aurora PostgreSQL は非対応) |
| 最大 Backtrack 期間 | 72時間 |
| コスト | 変更ログ保持量に応じた従量課金(DBストレージコストの10〜30%程度) |
| 主な用途 | 誤 DELETE / 誤 UPDATE / 誤 DROP TABLE の即時復旧 |
| 制限 | Binary Log との併用不可 / Cross-Region レプリカへの伝播なし |
resource "aws_rds_cluster" "aurora_mysql" {
cluster_identifier= "prod-aurora-mysql"
engine= "aurora-mysql"
engine_version = "8.0.mysql_aurora.3.05.2"
backtrack_window = 259200
backup_retention_period= 14
preferred_backup_window= "18:00-19:00"
preferred_maintenance_window = "sun:19:00-sun:20:00"
storage_encrypted = true
kms_key_id = aws_kms_key.rds.arn
tags = {
Environment= "production"
BackupEnabled = "true"
}
}
Backtrack 実行手順(誤操作後の巻き戻し):
# Backtrack 可能な最古時刻を確認
aws rds describe-db-clusters \
--db-cluster-identifier prod-aurora-mysql \
--query 'DBClusters[0].EarliestBacktrackTime'
# 誤操作前の時刻(例: JST 11:30 → UTC 02:30)に Backtrack
aws rds backtrack-db-cluster \
--db-cluster-identifier prod-aurora-mysql \
--backtrack-to "2026-05-14T02:30:00Z" \
--force-apply-early-backtrack-period
# Backtrack ステータスを確認(PENDING → COMPLETED)
aws rds describe-db-cluster-backtracks \
--db-cluster-identifier prod-aurora-mysql \
--query 'DBClusterBacktracks[0].{Status:Status,BacktrackTo:BacktrackTo}'
Backtrack 中はクラスターが一時停止するため、Backtrack 開始前にアプリケーションの DB 接続を切断すること。Aurora PostgreSQL の短期復旧は PITR を使用する(次節 6.3 参照)。
- Backtrack: 72時間以内の操作ミス即時復旧(RTO: 数分)— Aurora MySQL 専用
- Snapshot Restore: 長期保持 + 別クラスター復元(RTO: 20〜60分)— 全エンジン対応
- Aurora Global Failover: Region 障害時の Promoted 切り替え(RTO: 5分以内)
- Aurora PostgreSQL の短期復旧は PITR(秒単位・最大35日)を使用する
- 本番誤操作手順書には Backtrack 実行ステップと権限者を明記すること
6.3 PITR (Point-In-Time Recovery) 設計 — RDS/Aurora/DynamoDB 別
PITR は任意の時点(秒単位)への復元を可能にする機能。各サービスで保持期間と操作方法が異なる。
| サービス | PITR 保持期間 | 最小 RPO | 復元先 | デフォルト状態 |
|---|---|---|---|---|
| RDS | 1〜35日 | 5分 | 新インスタンス | 有効(7日) |
| Aurora | 1〜35日 | 1分 | 新クラスター | 有効(7日) |
| DynamoDB | 最大 35日間 | 秒単位 | 既存または新テーブル | 無効 |
DynamoDB PITR はデフォルト無効のため、本番テーブル作成時に明示的に有効化すること。
resource "aws_rds_cluster" "aurora_pg" {
cluster_identifier= "prod-aurora-pg"
engine= "aurora-postgresql"
engine_version = "16.4"
backup_retention_period = 35
preferred_backup_window = "17:00-18:00"
storage_encrypted = true
kms_key_id = aws_kms_key.rds.arn
tags = {
Environment= "production"
BackupEnabled = "true"
}
}
DynamoDB PITR の有効化(Terraform):
resource "aws_dynamodb_table" "orders" {
name= "orders"
billing_mode = "PAY_PER_REQUEST"
hash_key = "order_id"
attribute {
name = "order_id"
type = "S"
}
point_in_time_recovery {
enabled = true
}
server_side_encryption {
enabled = true
}
tags = {
Environment= "production"
BackupEnabled = "true"
}
}
DynamoDB PITR 復元(AWS CLI):
aws dynamodb restore-table-to-point-in-time \
--source-table-name orders \
--target-table-name orders-restored-20260514 \
--restore-date-time 2026-05-14T02:00:00.000Z \
--sse-specification-override '{"SSEType":"KMS","KMSMasterKeyId":"alias/aws/dynamodb"}'
RDS/Aurora の
backup_retention_period = 0 設定は自動バックアップ(PITR)を完全無効化する。コスト削減目的で開発環境に適用した設定が本番に誤適用されると、障害時に直前復元の手段が完全に失われる。DynamoDB PITR も point_in_time_recovery { enabled = false } がデフォルト状態であり、全本番テーブルに明示的な有効化が必須。必須チェックリスト
- RDS/Aurora:
backup_retention_period ≥ 7(本番推奨 35日) - DynamoDB:
point_in_time_recovery { enabled = true }を全テーブルで明示 - AWS Config Rule
db-instance-backup-enabled/dynamodb-pitr-enabledで継続監視 - 四半期1回の PITR 復元演習で RTO を計測・記録する
6.4 Snapshot Lifecycle Policy — 多段保持 + Cold Storage 最適化
Snapshot 保持期間の設計は「日次・週次・月次・年次」の多段構成が本番標準。AWS Backup の Lifecycle 設定で Glacier Instant Retrieval(Cold Storage)への自動移行と自動削除を管理する。
| 階層 | 頻度 | 保持期間 | Cold Storage 移行 | 用途 |
|---|---|---|---|---|
| 日次 | 毎日 03:00 JST | 14日 | なし | 短期復旧(週1以内の誤操作) |
| 週次 | 毎週月曜 04:00 JST | 90日 | 30日後 | 月次障害調査・週次監査 |
| 月次 | 毎月1日 05:00 JST | 365日 | 90日後 | コンプライアンス対応 |
| 年次 | 毎年1月1日 | 7年 | 180日後 | 規制要件(金融・医療・PCI DSS) |
Cross-Region Snapshot コピーは Incremental Copy を必ず有効化する。初回フルコピー後は差分のみ転送されるため、転送コストを 60〜80% 削減できる。Full Copy を毎日実行するとデータ量に依存して月次 $100〜500 超になる。
Native Backup vs AWS Backup の使い分け:
| 用途 | 推奨アプローチ |
|---|---|
| 単一 DB の細かな保持期間管理 | Native Backup(Aurora 自動バックアップ・RDS 自動バックアップ) |
| 複数 DB の統合管理・監査証跡 | AWS Backup Plan(タグ一括管理) |
| Cross-Region / Cross-Account DR | AWS Backup の Copy Action |
| 操作ミス即時復旧(Aurora MySQL) | Aurora Backtrack(72時間以内) |
| 任意時点復元(秒単位) | PITR(Aurora/RDS/DynamoDB 全対応) |
6.5 AWS Backup Vault Lock — WORM 保護の選択基準
Vault Lock は Backup Vault に WORM (Write Once Read Many) 保護を適用し、バックアップの削除・変更を禁止する。規制業界(金融・医療・政府系)ではバックアップ保全期間中のデータ改ざん禁止が法的要件になる場合があり、Vault Lock で技術的統制を実装できる。
| モード | 解除可否 | Cooling-off 期間 | 適用場面 |
|---|---|---|---|
| Governance Mode | 管理者権限で解除可能 | なし | 一般的な保護 / 誤設定リカバリが必要な場合 |
| Compliance Mode | いかなる方法でも解除不可 | 72時間 | 金融・医療・PCI DSS 等の法的規制対応 |
resource "aws_backup_vault_lock_configuration" "production" {
backup_vault_name= aws_backup_vault.production.name
min_retention_days = 7
max_retention_days = 365
changeable_for_days = 3
}
changeable_for_days = 3 が Cooling-off 期間(72時間)。この期間内であれば設定変更が可能。期間経過後は Compliance Mode 同等の不変状態になる。
Vault Lock の Compliance Mode(Cooling-off 期間経過後)は AWS サポートを含むいかなる方法でも設定変更・解除ができない。保持期間の誤設定(例: 7年を誤って70年に設定)も修正不可能になる。
適用手順(厳守)
- Step 1: Governance Mode で Vault Lock を設定し、バックアップ取得・復元が正常に動作することを確認
- Step 2: Cooling-off 期間(72時間)中に設定値(min/max retention days)の誤りがないことを確認
- Step 3: 規制要件が明確に確認できた後のみ Compliance Mode に移行
- Step 4: Compliance Mode 適用後は変更不可として運用フローを整備する
6.6 バックアップコスト試算(月次目安)
| 項目 | 前提条件 | 月次コスト目安(東京リージョン) |
|---|---|---|
| Aurora バックアップストレージ | DB 100GB × 保持係数 2x | ~$20 |
| Aurora Backtrack ログ | 変更量 30GB/日 × 72時間保持 | ~$12 |
| DynamoDB PITR | テーブルサイズ 200GB | ~$8 |
| AWS Backup Cold Storage | 累積 Cold Storage 200GB | ~$2 |
| Cross-Region コピー(Incremental: Tokyo → Osaka) | 増分 50GB/月 | ~$5 |
| Vault Lock ストレージ | 保護対象 100GB | ~$2 |
| 月次合計(標準構成) | ~$49 |
Cross-Region 転送コストは Full Copy を毎日実行すると同容量で月次 $300 超になる。Incremental Copy への切り替えで 90%以上の削減が可能。コスト最適化の優先順位: ① Incremental Copy 有効化 → ② 古い Snapshot の Cold Storage 移行 → ③ Backtrack 期間の適正化の順で実施する。
本章(§6)は AWS Backup 統合管理の観点から RDS / Aurora / DynamoDB を横断したバックアップ戦略を解説する。Aurora 単体の詳細(連続バックアップの仕組み・クロスリージョン DR の設計・実際の Restore 手順・RDS Proxy + Failover 連携)については「Aurora Backup/Restore/DR シリーズ」(8節 deep-dive)を参照のこと。
- 原則1: AWS Backup Plan で RDS / Aurora / DynamoDB を一括管理し属人的設定を排除する
- 原則2: Aurora Backtrack は72時間以内の即時復旧専用 — 長期 DR は Snapshot + PITR で設計する
- 原則3: Vault Lock Compliance Mode は規制対応必須案件のみ — 誤設定は修正不可と理解して適用する
- 原則4: Cross-Region コピーは Incremental Copy で転送料金を最適化する
- 原則5: 四半期1回の Restore Drill で RTO を計測 — バックアップ取得だけでは復元保証にならない
日次バックアップが取得されていても、リストア演習を一度も実施したことがない構成は本番障害時に復元失敗する典型例。実際の障害時に初めてリストアを試みると、権限不足・暗号化キー失効・RTO 超過という3つの落とし穴に同時に直面する。最低でも四半期1回の Restore Drill を実施し、RTO(復旧所要時間)を計測・記録すること。AWS Backup の Restore Testing 機能を活用すれば自動化も可能。
7. 詰まりポイント7選 + アンチパターン演習5問
Vol2 で解説した4本柱(DMS / Aurora Global Database / DynamoDB Streams / AWS Backup)の本番運用で頻出する詰まりポイントを7選 + アンチパターン演習5問に厳選した。単純な設定漏れから複合的な設計判断ミスまで、実際の本番運用で遭遇する典型例を Before/After 形式で解説する。
詰まり1: DMS LOB 移行でのデータ欠損(Limited LOB の罠)
症状: Oracle から Aurora PostgreSQL へ DMS フルロード後、CLOB/BLOB 列のデータが切り詰められている、または NULL になっている。
Before(問題のある設定):
replication_task_settings = jsonencode({
TargetMetadata = {
SupportLobs = true
FullLobMode = false
LobChunkSize = 0
LimitedSizeLobMode = true
LobMaxSize= 32
}
})
LimitedSizeLobMode = true + LobMaxSize = 32(KB)の設定では、32KB 超の LOB データが黙って切り詰められる。Oracle の CLOB に格納された長文テキストが欠損する。
After(修正後):
replication_task_settings = jsonencode({
TargetMetadata = {
SupportLobs = true
FullLobMode = true
LobChunkSize = 64
LimitedSizeLobMode = false
LobMaxSize= 0
}
})
FullLobMode = true に切り替え、LobChunkSize = 64(KB)で LOB を分割転送する。Full LOB Mode はスループットが低下するため、LOB 列を含むテーブルのみを別タスクに分けて並列実行する設計が望ましい。
詰まり2: スキーマ差異による DMS 変換エラー(SCT 未使用の罠)
症状: DMS レプリケーションタスク開始後、大量の「Column X not found」「Data type mismatch」エラーが Task Log に溢れ、多くのレコードが Skip される。
Before(問題のある手順):
SCT(Schema Conversion Tool)を使わず、Oracle スキーマ定義をそのまま Aurora PostgreSQL に手動移行。Oracle 固有のデータ型(NUMBER(10,2)・DATE・VARCHAR2)が PostgreSQL との型定義の差異を見落としている。
After(修正後の手順):
# SCT CLI で Assessment Report を生成(GUI でも可)
# 1. SCT でソース DB(Oracle)とターゲット DB(Aurora PostgreSQL)を接続
# 2. Assessment Report を生成
# 3. "Action Items" を全件確認し手動変換が必要な箇所を特定・修正
# SCT が変換できない代表的なケース
# - Oracle ROWID 依存のインデックス → シーケンス + PK に変換
# - Oracle Sequence の CURRVAL → PostgreSQL の nextval() に変換
# - Oracle Package / Stored Procedure → PL/pgSQL に書き換え
SCT の Assessment Report で「High」「Medium」の Action Items を全件解消してから DMS タスクを開始すること。「Low」Action Items も蓄積すると CDC フェーズで問題が顕在化する。
詰まり3: Aurora Global Database Failback 忘れ(Primary 戻し忘れ)
症状: Aurora Global Database Failover 演習後、Secondary Region を Promote して Primary として運用を続けたが、旧 Primary(東京)への Failback を実施し忘れ、大阪リージョンからの書き込みが数ヶ月継続。コスト・レイテンシ両面で不利な状態が続く。
Before(Failover 後の放置状態):
Failover 前: Tokyo (Primary, Write) → Osaka (Secondary, Read-only)
Failover 後: Osaka (Promoted Primary, Write) → Tokyo (Detached, Read-only)
問題: Failback 手順が未定義 → Osaka が Primary のまま数ヶ月運用継続
After(Failback Runbook):
# Step 1: Replication Lag が 0 に近づくまで待機(最低 24時間)
aws rds describe-global-clusters \
--global-cluster-identifier prod-aurora-global \
--query 'GlobalClusters[0].GlobalClusterMembers[*].{DB:DBClusterArn,Writer:IsWriter}'
# Step 2: Lag 確認後、再度 Failover(東京を Primary に戻す)
aws rds failover-global-cluster \
--global-cluster-identifier prod-aurora-global \
--target-db-cluster-identifier \
arn:aws:rds:ap-northeast-1:123456789012:cluster:prod-aurora-tokyo
Failback は Replication Catch-up が十分(Lag ほぼ 0) であることを確認してから実行する。急いで Failback するとデータ整合性が取れない場合がある。Failover Runbook には Failback 手順と RTO 計測ステップを必ず含めること。
詰まり4: DynamoDB Streams 24時間保持限界を超えた Consumer 遅延
症状: Lambda の Deploy 失敗・権限変更・スロットリングにより Lambda 処理が24時間以上停止。DynamoDB Streams の保持期間(最大24時間固定)を超え、その間の変更レコードが永久に失われた。
Before(24時間以内しか保証されない構成):
DynamoDB Table → DynamoDB Streams → Lambda(ESM)
問題: Lambda が24時間以上停止 → その間の変更レコードが永久に失われる
After(KDS 連携で保持期間を 7日〜365日に延長):
resource "aws_kinesis_stream" "orders_cdc" {
name = "orders-change-data-capture"
shard_count= 4
retention_period = 168
encryption_type = "KMS"
kms_key_id= "alias/aws/kinesis"
tags = {
Environment = "production"
}
}
resource "aws_dynamodb_kinesis_streaming_destination" "orders" {
stream_arn = aws_kinesis_stream.orders_cdc.arn
table_name = aws_dynamodb_table.orders.name
}
DynamoDB → KDS(保持 7日・Extended Retention で最大 365日)への移行で根本解決。既存 DynamoDB Streams 構成は「Iterator Age が 12時間超過で即エスカレーション」アラートを必ず設定し、24時間の半分をシグナルとして使う。
詰まり5: Global Tables Conflict 解決漏れ(LWW 競合でデータ消失)
症状: DynamoDB Global Tables を ap-northeast-1 と us-east-1 で双方向運用中、注文の status が「PAID → PENDING」に戻っている事象が断続的に発生。原因は LWW(Last Writer Wins)Conflict。
Before(Conflict 解決なし):
import boto3
dynamodb = boto3.resource("dynamodb", region_name="ap-northeast-1")
table = dynamodb.Table("orders-global")
def update_order_status(order_id, new_status):
table.update_item(
Key={"order_id": order_id},
UpdateExpression="SET #s = :status",
ExpressionAttributeNames={"#s": "status"},
ExpressionAttributeValues={":status": new_status}
)
Region 間で Conflict が発生した場合、LWW により後書きの Region の値が勝つ。Application 側で検知できないまま重要データが上書きされる。
After(Version Attribute + 楽観的ロック):
import boto3
from botocore.exceptions import ClientError
dynamodb = boto3.resource("dynamodb", region_name="ap-northeast-1")
table = dynamodb.Table("orders-global")
def update_order_status(order_id, new_status, expected_version):
try:
response = table.update_item(
Key={"order_id": order_id},
UpdateExpression="SET #s = :status, version = :new_ver",
ConditionExpression="version = :expected",
ExpressionAttributeNames={"#s": "status"},
ExpressionAttributeValues={
":status": new_status,
":new_ver": expected_version + 1,
":expected": expected_version,
},
ReturnValues="ALL_NEW",
)
return response["Attributes"]
except ClientError as e:
if e.response["Error"]["Code"] == "ConditionalCheckFailedException":
current = table.get_item(Key={"order_id": order_id})["Item"]
raise ValueError(
f"Conflict: expected version={expected_version}, "
f"actual={current.get('version')}"
)
raise
ConditionExpression で楽観的ロックを実装し、Conflict を ConditionalCheckFailedException として検知する。アプリケーションで再試行またはエラーハンドリングを実装することで、黙ったデータ上書きを防ぐ。
詰まり6: Backup Restore 時間の過小評価(RPO/RTO 試算ミス)
症状: 障害発生時に Aurora Snapshot からの復元を試みたところ、Restore 完了まで 45分かかり、SLA の RTO(30分)を大幅に超過した。
Before(RTO 計測なし):
想定: Snapshot から Restore → 約15分で完了(体感)
実際: 100GB Aurora クラスター → Restore 完了: ~45分
Parameter Group 適用 → さらに +10分
アプリケーション接続切り替え → さらに +5分
合計 RTO: 60分(SLA: 30分を超過)
After(Restore Drill で RTO を計測):
| 項目 | 計測値 | 対策 |
|---|---|---|
| Snapshot Restore 時間 | 45分(100GB) | Aurora Clone + RDS Proxy Failover で短縮 |
| Parameter Group 適用 | 10分 | カスタム Parameter Group を事前適用済みクラスターを目標 |
| DNS 切り替え(CNAME) | 5分 | Route 53 Failover Record で自動化 |
| アプリ接続確認 | 10分 | ヘルスチェック自動化 |
| 合計 RTO | 70分 | RDS Proxy + Failover で目標 30分以内を目指す |
四半期1回の Restore Drill で実際の RTO を計測・記録し、SLA との乖離を把握すること。想定 RTO と実測 RTO のギャップが最も大きい落とし穴がここにある。
詰まり7: Cross-Region Snapshot 転送コスト爆発(コスト試算なし)
症状: Tokyo → Osaka の Cross-Region Snapshot コピーを Full Copy で毎日実行。DBサイズ 500GB のため月次の転送コストが $500 超になっていることに気づかず、請求書で発覚。
Before(Full Copy 毎日):
Tokyo → Osaka Full Copy: 500GB × $0.02/GB × 30日 = ~$300(転送のみ)
Snapshot 保管 + 転送料金で合計 ~$500 超
After(Incremental Copy + Cold Storage 最適化):
resource "aws_backup_plan" "optimized" {
name = "prod-backup-plan-optimized"
rule {
rule_name= "daily-incremental-osaka"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 18 * * ? *)"
lifecycle {
delete_after = 14
}
copy_action {
destination_vault_arn = aws_backup_vault.dr_osaka.arn
lifecycle {
cold_storage_after = 3
delete_after = 7
}
}
}
rule {
rule_name= "weekly-full-osaka"
target_vault_name = aws_backup_vault.production.name
schedule = "cron(0 19 ? * 1 *)"
lifecycle {
cold_storage_after = 30
delete_after = 90
}
copy_action {
destination_vault_arn = aws_backup_vault.dr_osaka.arn
lifecycle {
cold_storage_after = 30
delete_after = 90
}
}
}
}
| 構成 | 月次コスト目安 |
|---|---|
| Full Copy 毎日(500GB) | ~$300(転送)+ ~$200(保管)= ~$500 |
| Incremental Copy 日次 + Full Copy 週次 | ~$20(転送)+ ~$50(保管)= ~$70 |
| 削減効果 | 86% 削減 |
Cross-Region Snapshot を設計する際は必ず月次コスト試算を実施し、Incremental Copy 有効化を前提とした設計にすること。
- 演習1: Oracle 12c → Aurora PostgreSQL 移行 — SCT Assessment Report で「High」Action Items が 30件検出。DMS Full Load を先行実施してよいか? → 全件解消してから DMS を実行。「High」残存時は変換エラー多発・データ欠損のリスク。
- 演習2: Aurora Global Database を東京 (Primary) + 大阪 + バージニア (Secondary) で構成中、東京で障害発生。大阪を Promote した後の Failback 手順と、最低待機時間は? → Replication Lag ほぼ 0 + 最低24時間待機後に Failover で東京を Primary に戻す。
- 演習3: DynamoDB Streams + Lambda 構成で Lambda の Deploy 失敗が17時間続いた。残り7時間で Stream 保持期限が切れる。どう対応するか? → Lambda を即時修復して処理再開し Iterator Age を監視。並行して Kinesis Data Streams 移行計画を立案。根本対策は KDS 連携。
- 演習4: AWS Backup Plan で Aurora + DynamoDB を一括バックアップ中。Vault Lock Compliance Mode を設定したが min_retention_days を誤って 3650日(10年)に設定してしまった。修正できるか? → Cooling-off 期間(72時間)内であれば修正可能。期間経過後は修正不可。今後は Governance Mode で検証後に Compliance Mode を適用する手順を義務化。
- 演習5: Tokyo → Osaka の Cross-Region Snapshot コピーを Full Copy で毎日実行中(DB 300GB)。月次転送コストが $180 発生している。コストを70%以上削減するにはどうするか? → Incremental Copy 有効化 + 日次 Incremental / 週次 Full の多段設計に変更。Cold Storage 移行の Lifecycle Policy も追加。
- DMS: SCT の Schema Action Report で「High」「Medium」の全件解消を DMS 開始前に確認したか
- Aurora Global: Failback は Replication Lag ほぼ 0 + 最低24時間待機後に実行したか
- DynamoDB Streams: Iterator Age が 12時間超過で即エスカレーション・24時間超過は KDS 移行の契機としたか
- Vault Lock: Compliance Mode 適用前に Governance Mode で72時間以上の動作確認を実施したか
- Cross-Region コピー: Incremental Copy 有効化 + 月次コスト試算を設計時に実施したか
8. まとめ + Vol3予告 + 落とし穴10選 + 全12軸+Database Vol1+Vol2+Serverless Vol1+Vol2 クロスリンク
Vol2 で学んだ DMS / Aurora Global Database / DynamoDB Streams / AWS Backup の4本柱は、Database 運用の「静的管理」から「ライフサイクル全体の動的管理」への進化を表している。Vol1(RDS / Aurora / DynamoDB 基礎運用)の土台の上に Vol2 の4本柱を重ねることで、移行・グローバル展開・ストリーミング・バックアップ戦略の完全なサイクルが閉じる。
8.1 Vol2 習得チェックリスト
| 習得項目 | チェック内容 | 確認指標 |
|---|---|---|
| DMS 設計 | DMS Replication Instance のサイジング + Full Load + CDC 連続移行が設計できる | DMS Task Log でエラー率 < 0.01% |
| DMS LOB 設計 | SCT Assessment Report の Action Items を全件解消できる | High/Medium = 0件 確認済み |
| DMS LOB 設計 | Full LOB Mode と Limited LOB Mode の使い分けを説明できる | LOB 欠損レコード = 0件 |
| Aurora Global 設計 | Secondary Region への Replication Lag を 1秒以下で維持できる | CloudWatch AuroraGlobalDBReplicationLag ≤ 1000ms |
| Aurora Global 運用 | Failover/Failback Runbook を手順書として整備できる | 四半期演習で RTO 計測済み |
| Streams 設計 | ESM の parallelization_factor / bisect_batch_on_function_error を設定できる | Iterator Age < 30秒 を維持 |
| Streams 設計 | 24時間制限への対策(KDS 移行 or DLQ 必須)を実装できる | DLQ メッセージ数アラート設定済み |
| Backup 設計 | AWS Backup Plan の多段設計(日次/週次/月次)を Terraform で実装できる | Backup Job 成功率 100% |
| Backup 設計 | Vault Lock の Governance/Compliance 選択基準を説明できる | 規制要件に対応したモード選択の根拠を文書化 |
| コスト最適化 | Cross-Region Snapshot の Incremental Copy を有効化できる | 月次コストレポートで転送費を確認 |
8.2 落とし穴10選 — Vol1 + Vol2 全領域横断チェックリスト
- 落とし穴1 (Vol1): RDS Multi-AZ の Failover 切り替えが 1〜2分かかることを想定せず、アプリケーションの DB 接続タイムアウトを短く設定していた → 接続タイムアウト値を Multi-AZ Failover 時間より長く設定する
- 落とし穴2 (Vol1): Aurora 自動スケーリングが Read Replica を追加するまでに 5〜15分かかることを把握せず、突発的なトラフィック増加時にすべての Read Replica が飽和した → 事前プロビジョニング + Warm Pool 設計
- 落とし穴3 (Vol1): DynamoDB の Hot Partition 問題を Partition Key 設計前に考慮しなかった → 高カーディナリティな PK + ランダムサフィックス設計
- 落とし穴4 (Vol2): DMS Full LOB Mode のパフォーマンス影響を試算せずに本番移行した → LOB 列を含むテーブルのみを別タスクに分けて並列実行
- 落とし穴5 (Vol2): SCT の Action Items を確認せずに DMS タスクを実行し、大量の変換エラーが発生した → SCT High/Medium = 0件を DMS 開始前の必須条件に
- 落とし穴6 (Vol2): Aurora Global Failback を Replication Catch-up なしで急いで実行し、データ整合性が崩れた → Failback 前に Lag ほぼ 0 + 最低24時間待機を義務化
- 落とし穴7 (Vol2): DynamoDB Streams の 24時間制限を知らずに Lambda 処理遅延を放置し、変更レコードが消失した → Iterator Age 12時間超過で即エスカレーション + KDS 移行
- 落とし穴8 (Vol2): Global Tables の LWW Conflict 解決を実装せずに双方向書き込みを許可し、重要データが無通知で上書きされた → Version Attribute + Condition Expression で楽観的ロック実装
- 落とし穴9 (Vol2): Vault Lock Compliance Mode を Governance Mode での検証なしに直接適用し、保持期間の誤設定が修正不可能になった → Governance Mode で72時間以上確認後に Compliance Mode へ移行
- 落とし穴10 (Vol2): Cross-Region Snapshot を Full Copy で毎日実行し転送コストが月次 $500 超に爆発した → Incremental Copy 有効化 + 月次コスト試算を設計段階で必須化
8.3 Vol2 4本柱 本番設定 クイックリファレンス
| カテゴリ | パラメータ | 本番推奨値 | 備考 |
|---|---|---|---|
| DMS | Replication Instance クラス | r5.2xlarge 以上 | Full LOB Mode + CDC 同時実行時 |
| DMS | LOB Mode | FullLobMode = true | Limited LOB は欠損リスクあり |
| DMS | LobChunkSize | 64KB | LOB サイズの最大値に合わせて調整 |
| DMS | TablePreparationMode | truncate | Full Load 再実行時の安全策 |
| Aurora Global | Replication Lag 警告閾値 | 1000ms (1秒) | Critical: 5000ms |
| Aurora Global | Failover 待機時間 | 5分以内 | Failback 最低待機: 24時間 |
| Aurora Global | Backtrack 期間 | 259200秒 (72時間) | Aurora MySQL 専用 |
| DynamoDB Streams | batch_size | 10〜100 | 大きいほど効率的、失敗時影響大 |
| DynamoDB Streams | parallelization_factor | 1〜10(段階的引き上げ) | Iterator Age 増大時に引き上げ |
| DynamoDB Streams | maximum_retry_attempts | 3 | -1(無制限)は本番禁止 |
| DynamoDB Streams | Iterator Age 警告閾値 | 300000ms (5分) | Critical: 1800000ms (30分) |
| AWS Backup | 日次保持期間 | 14日 | Cold Storage 移行なし |
| AWS Backup | 週次保持期間 | 90日 | 30日後 Cold Storage 移行 |
| AWS Backup | Vault Lock Cooling-off | 3日 (72時間) | Compliance Mode 適用前の検証期間 |
| PITR | RDS/Aurora 保持期間 | 35日 | 最小 7日(本番推奨 35日) |
| PITR | DynamoDB 有効化 | enabled = true | デフォルト無効 — 明示的に有効化必須 |
8.4 Vol3 予告 — 特化型 Database 本番運用
Vol1(基礎3本柱)・Vol2(進化4本柱)で RDS / Aurora / DynamoDB / DMS / Global Tables / AWS Backup の本番運用を完成させた。Vol3 は特化型 Database の本番運用に踏み込む。
| Vol3 対象サービス | 主な特徴 | 代表ユースケース |
|---|---|---|
| ElastiCache (Redis / Memcached) | インメモリキャッシュ / Sub-millisecond レイテンシ | セッション管理・レート制限・リアルタイムランキング |
| Neptune | グラフデータベース / Property Graph + RDF | ソーシャルグラフ・不正検知・レコメンデーション |
| DocumentDB (MongoDB互換) | ドキュメント指向 / JSON 格納 | コンテンツ管理・カタログ・IoT データ |
| Timestream | 時系列特化 / 自動階層化ストレージ | IoT センサー・メトリクス・金融時系列 |
| Keyspaces (Cassandra互換) | 高スループット書き込み / Multi-Region | IoT 大量書き込み・ログ収集 |
Vol3 では「ElastiCache Redis Cluster Mode × DynamoDB DAX との使い分け」「Neptune Graph Query 最適化」「Timestream の Multi-measure Records 設計」など、特化型 DB の本番設計パターンを解説予定。
8.5 Database Vol1 ↔ Vol2 双方向リンク + 全12軸クロスリンク
- ← Database Vol1(RDS × Aurora × DynamoDB 基礎運用): 基礎3本柱の Multi-AZ / Read Replica / Partition Key 設計
- → 本記事 Vol2: DMS × Aurora Global × Streams × AWS Backup の4本柱進化運用
- →→ Vol3: Database本番運用 Vol3 (ElastiCache×DAX×MemoryDB キャッシュ戦略完全ガイド)
- →→→ Vol4: Database本番運用 Vol4 (2024-2025最新機能: Aurora DSQL × Limitless × DynamoDB Strong Consistency)
Vol1 + Vol2 統合で「設計→構築→運用→移行→DR→バックアップ」の Database フルライフサイクルが完成する。
- DMS / Aurora Global / DynamoDB Streams / AWS Backup の4本柱を用途別に選定できる
- LOB制限 / Replication Lag / Iterator Age / Vault Lock の本番パラメータを設計できる
- Vol1 基礎運用と組み合わせた Database フルライフサイクル管理を構築できる
- 移行失敗 / Failover RTO違反 / Backup未復元 などの典型障害を未然に防げる
- Vol1+Vol2 横断 落とし穴10選を把握し、設計段階でリスクを潰せる
- 第1軸 IAM (4記事): Vol1 / Vol2 / Vol3 / Vol4
- 第2軸 EKS本番運用 (3記事): Vol1 / Vol2 / Vol3
- 第3軸 復旧・運用 (4記事): Vol1 / Vol2 / Vol3 / Vol4
- 第4軸 生成AI (2記事): Vol1 Bedrock Agents / Vol2 Knowledge Bases / ML/AI本番運用Vol2 (Bedrock Embedding×RAG×KB×Agents)
- 第5軸 セキュリティ (3記事): Vol1 / Vol2 SOC統合 / Vol3 IAM Access Analyzer×KMS
- 第6軸 コスト最適化 (1記事): Vol1 Cost Explorer × Budgets
- 第7軸 マルチアカウント運用 (1記事): Vol1 Organizations × Control Tower
- 第8軸 Observability (2記事): Vol1 Application Signals × SLO × X-Ray / Vol2 CloudWatch Logs深掘り編
- 第9軸 Network/VPC設計 (2記事): Vol1 Transit Gateway × VPC Lattice / Vol2 Hybrid Connectivity
- 第10軸 DevOps/CI/CD (2記事): Vol1 CodePipeline / Vol2 Container × SAM
- 第11軸 Database本番運用 (4記事): Vol1 RDS × Aurora × DynamoDB / 本記事 Vol2 DMS × Aurora Global × Streams × Backup / Vol3: ElastiCache × DAX × MemoryDB キャッシュ戦略完全ガイド / Vol4: Aurora DSQL × Limitless × DynamoDB Strong Consistency
- 第12軸 Serverless本番運用 (2記事): Vol1 Lambda × API GW × Step Functions / Vol2 EventBridge × SQS × SNS × Kinesis
- Step Functions入門: ASL × Standard/Express × エラーハンドリング入門
- Container本番運用 Vol1: ECS × Fargate × ECR × ECS Exec × Service Connect 完全ガイド / Vol2 EKS×ArgoCD GitOps編
- Storage本番運用 Vol1: S3 × EFS × FSx × Storage Gateway 完全ガイド
- Storage Vol2 (S3 Advanced): S3 Advanced Lifecycle×Intelligent-Tiering×Object Lambda×Express×CRR 完全ガイド
- Edge/CDN本番運用 Vol1: CloudFront × Lambda@Edge × Route53 完全ガイド
- Analytics/Data Lake Vol1 (Glue / Athena / Redshift Serverless / Lake Formation / QuickSight) ← DMS → S3 → Athena パイプライン
- 統合本番運用: EventBridge × VPC Lattice × Fargate 統合本番運用 — イベント駆動マイクロサービス
DMS CDC / MGN Cutover / Snow Family転送 / Application Migration Service による本番クラウド移行の完全ガイド。
Migration本番運用 Vol1 を読む →
Vol2 完結宣言: Vol1 で RDS / Aurora / DynamoDB の基礎3本柱を習得し、Vol2 で DMS / Aurora Global Database / DynamoDB Streams / AWS Backup の進化4本柱を完成させた。これにより「設計→構築→運用→移行→グローバル展開→ストリーミング連携→バックアップ戦略」の Database フルライフサイクルが一本の設計思想で接続される。全12軸のうち第11軸 Database 本番運用 Vol1+Vol2 を完遂した読者は、残る第12軸 Serverless 本番運用 Vol1+Vol2 と合わせて、AWS 本番運用の全領域をカバーする統合設計力を手にしたことになる。
Vol1: RDS × Aurora × DynamoDB 基礎運用に戻る
Database本番運用 Vol4 — Aurora DSQL × Limitless × DynamoDB Strong Consistency (2024-2025最新機能)
Database本番運用 Vol5 — Neptune・DocumentDB・Keyspaces・Timestream 用途特化DB本番運用